How derivedStateOf works: a deep d(er)ive

Compose's snapshot system is really neat, as I've talked and written about before. Once you know how it works, you can do some cool tricks with it, and derivedStateOf is a rich example of this. I recently gave a talk focused more on explaining the algorithms with animated diagrams, so this article will focus on code, including examples from the actual Compose source.
Jetpack Compose is a reactive framework, which means it automatically reacts to state changes. This reactivity is built on top of the snapshot state library within Compose. If you haven't read Introduction to the Compose Snapshot system and watched Opening the shutter on snapshots, I would recommend doing that before going much further in this post.
 Zach Klippenstein
Zach Klippenstein Zach Klippenstein
Zach Klippenstein
Meet derivedStateOf
derivedStateOf, you might want to jump to the section on Mechanics.derivedStateOf is a function in the Compose runtime that returns a State object. It returns a State, not a MutableState, so you can't directly manipulate its value, unlike what you get from mutableStateOf. It's defined like this (source):
fun <T> derivedStateOf(
policy: SnapshotMutationPolicy<T>,
calculation: () -> T,
): State<T>You use it like this:
@Composable fun Foo() {
val derived: State<…> = remember {
derivedStateOf(structuralEqualityPolicy()) {
// Perform some calculation by reading other state objects.
}
}
// Do something with derived.value.
}derivedStateOf that does not take a policy parameter, but the Compose team recommends you avoid it since it will default to neverEqualPolicy() in some cases.Terms
- restartable function — A function that may be re-executed at some point in the future, usually because some state that it read changed. See Restartable functions from first principles for more information.
- (state) dependency — A state object that is read by the calculation function of a
derivedStateOf.
One other note: I'll often refer to “the derivedStateOf object”. derivedStateOf itself is actually just a factory function, the class of the object it returns is actually an internal class called DerivedSnapshotState, but they have a one-to-one relationship, so I'll just use the name of the factory function to refer to the object it returns.
What's it for?
There are some really good articles with lots of diagrams dedicated to the matter of when to use derivedStateOf. I'd highly recommend reading this article by Google DevRel Ben Trengrove, as well as this other article, and of course the official Compose docs (although they are a bit terse). These articles explain when/where, but do not get into much detail about why. But before we dive in, let's review what not to use it for.
Sometimes, you need to perform a calculation with one, two, or more state objects. For example, you might want to calculate the length of a string:
@Composable fun MessageField() {
var text by remember { mutableStateOf("") }
val textLength = text.length
Column {
TextField(text, onValueChange = { text = it })
Text("You've entered $textLength characters.")
}
}As far as calculations go this one isn't very interesting, but importantly it is:
- Reading the value of the state object, and
- Deriving another value from the state object's value.
This is more apparent if we get rid of the delegated property syntactic sugar:
@Composable fun MessageField() {
val text = remember { mutableStateOf("") }
val textLength = text.value.length
Column {
TextField(text.value, onValueChange = { text.value = it })
Text("You've entered $textLength characters.")
}
}text is now a val, not a var, it's initialized using = instead of by, and all the references to it use .value. References to textLength do not change because it's just a regular local variable, not a state object.
Every time text changes, e.g. because the user typed something, MessageField recomposes. It recomposes because text is read while MessageField is executing, both when initializing textLength and when it's passed to TextField. Note that Column is an inline function, and so any state reads that happen in its content function are tracked by its caller and its content function won't ever recompose on its own (if this surprises you, see Scoped recomposition in Jetpack Compose — what happens when state changes?).
textLength is a value that is derived from text. It is, technically, derived state. So we should use derivedStateOf, right? No.
derivedStateOf.textLength has the following properties:
- It is cheap to calculate. Getting the length of a string is a constant-time operation.
- It changes almost every time
textchanges, in practice. Inserting or deleting text are far more common text input operations than replacing a string with one of the exact same length.
There is a significant amount of overhead in derivedStateOf, as you'll see if you keep reading, and simple calculations like this are cheaper to just perform directly, even in composition. Here are some very unscientific charts that illustrate this point: using a derivedStateOf for a calculation that changes frequently (e.g. on every frame) just adds overhead without saving any work.
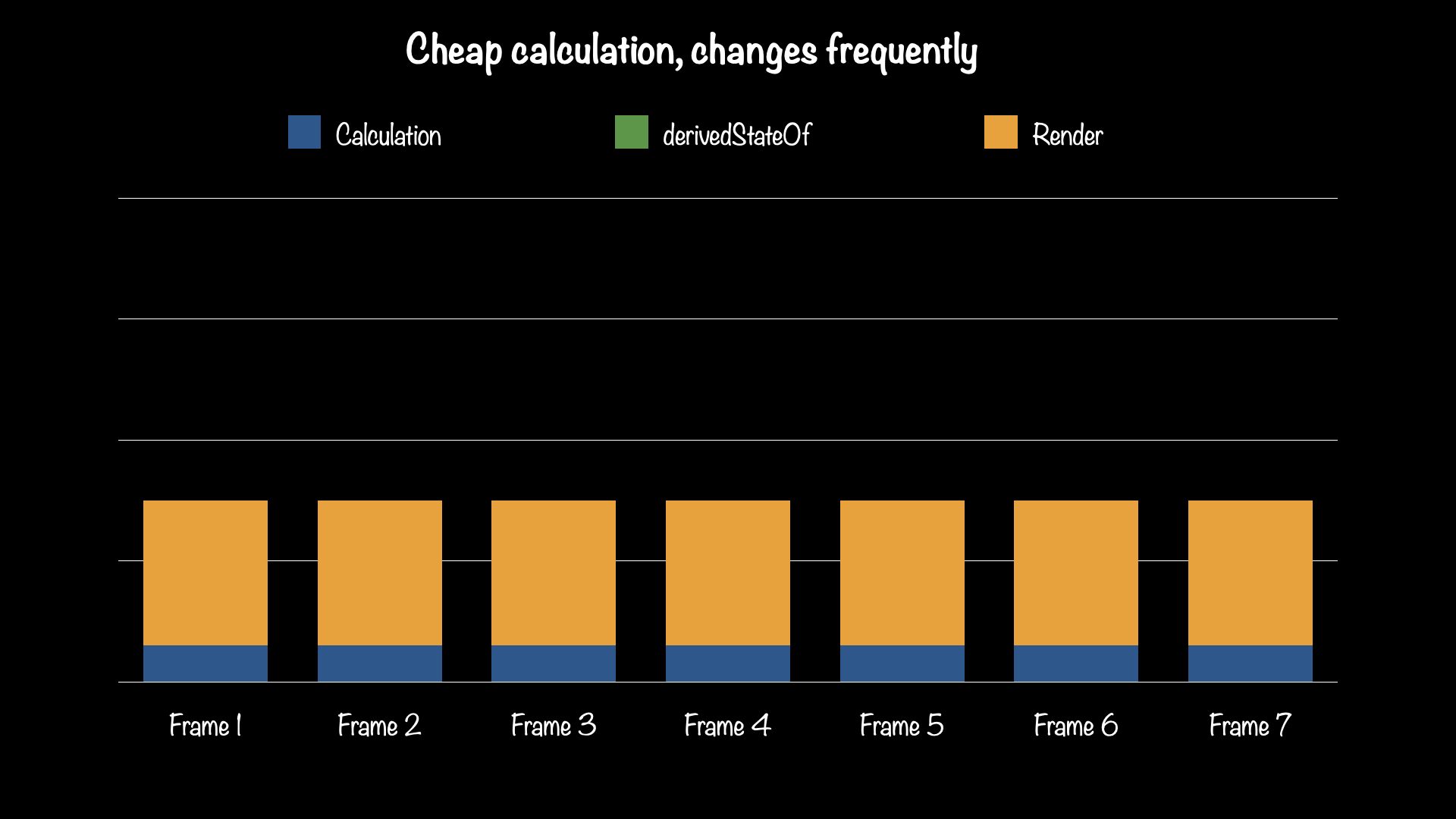
Left: derivedStateOf is not used. Right: derivedStateOf is used, but just makes things worse.
To see some examples of when derivedStateOf is the right tool for the job, read on.
Features
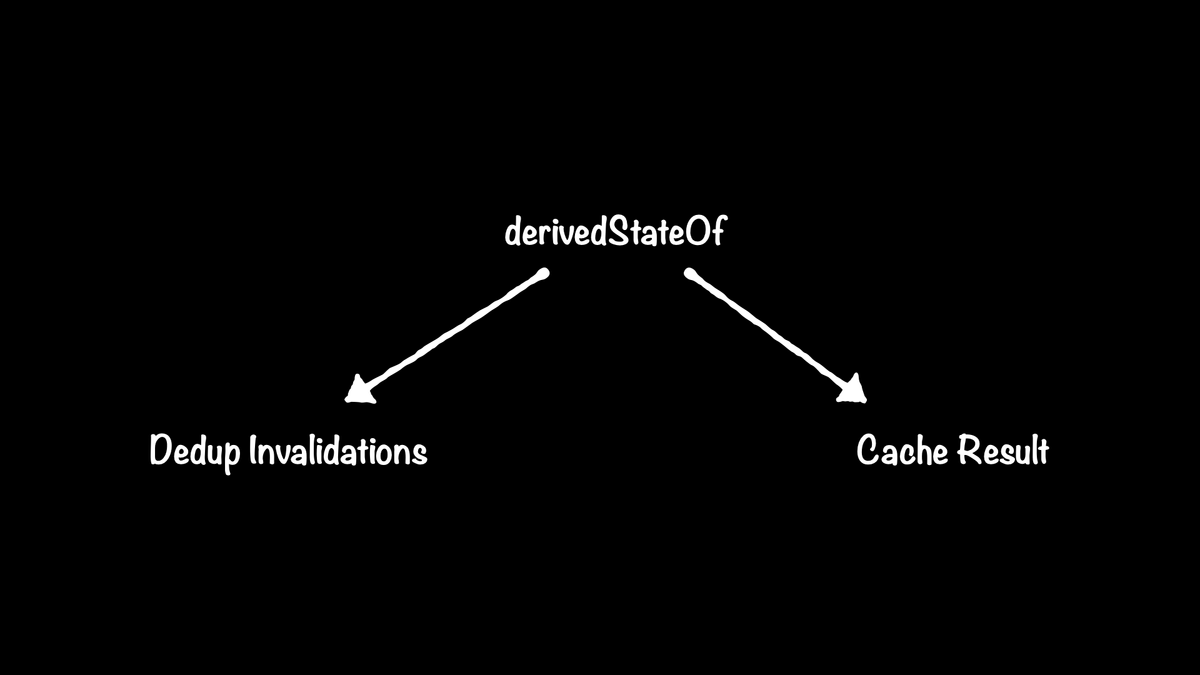
derivedStateOf has two key features:
- Reducing unnecessary invalidations of restartable functions.
- Caching the result of calculations.
Each of these features helps optimize for certain use cases. They each provide a benefit on their own, but they also take advantage of each other to make the whole work better than the sum of its parts.
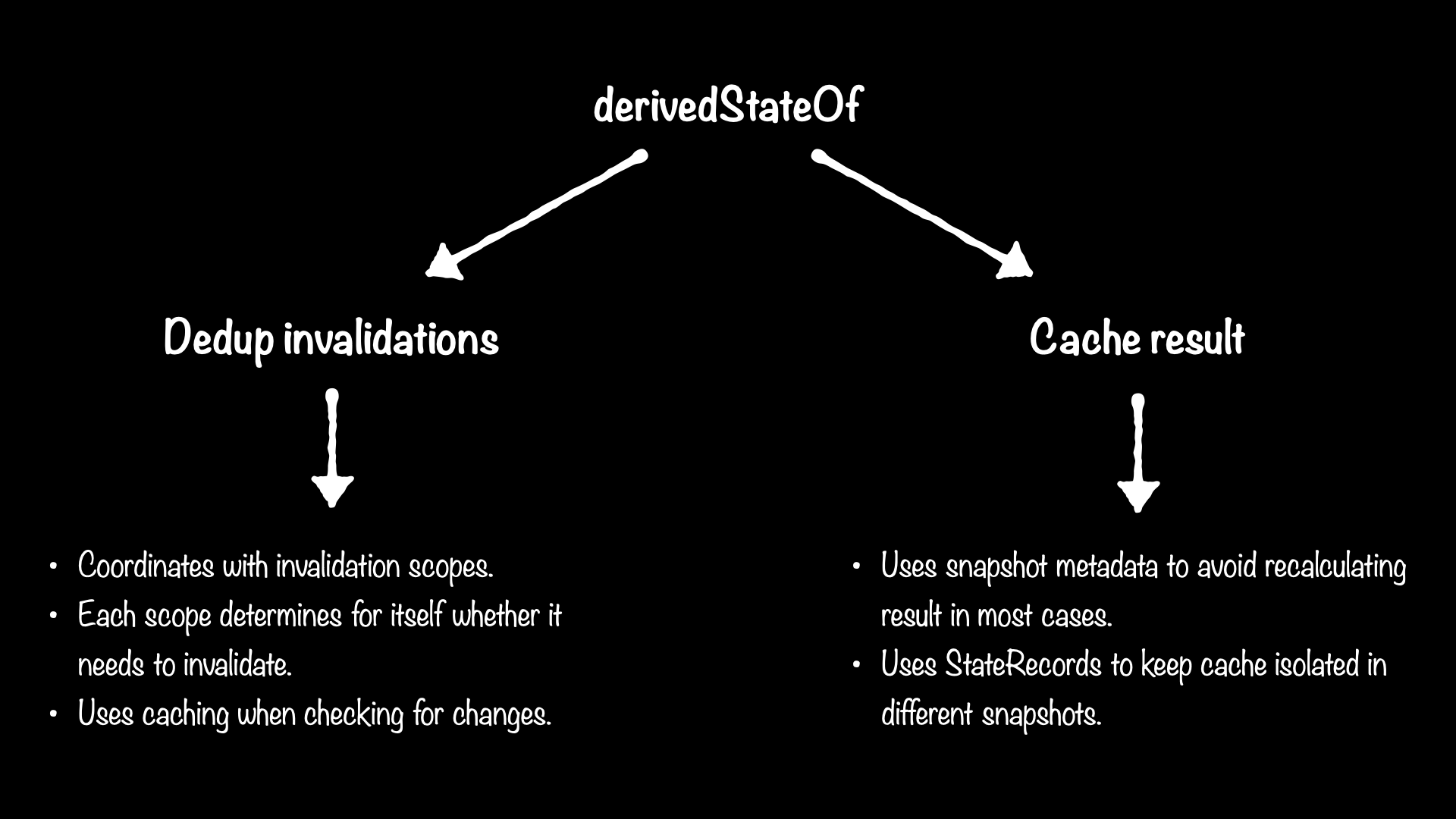
Deduping invalidations
Reducing unnecessary invalidations, both of composables and other restartable functions, is arguably the most important feature of derivedStateOf. A restartable function is invalidated when some state that it read is changed, where “invalidated” means it will be re-executed now or at some point in the future. For more information on “restartable functions”, see Restartable functions from first principles. I call this deduplicating, or “deduping”, invalidations because when a scope is invalidated and re-executed but output of the function (be it a tree of UI elements or the result of a snapshotFlow) hasn't changed, then the function will have already been invalidated for that state—so it's a duplicate invalidation. This is such an important feature because in many cases, invalidation is relatively expensive. Even though Compose tries to make re-executing a composable function or a layout measure block as cheap as possible, not running them is always cheaper than running them. For example, in the worst case, invalidating a composable function means (roughly):
- Marking the composable as needing recomposition.
- Requesting a screen frame from the Choreographer that otherwise wouldn't be needed.
- When the frame callback occurs:
- Re-running the dirty composable in a new snapshot.
- Re-recording any reads it does.
- Re-running any unskippable composables it calls.
- Potentially re-allocating any objects created by the composable that aren't memoized.
- In particular, it's quite common for composables to allocate new
Modifierelements created by the composable, which also requires diffing modifier lists.
- In particular, it's quite common for composables to allocate new
If nothing actually changed, then all that work is for naught. In contrast, detecting that a derivedStateOf output didn't change involves:
- Marking the composable as maybe needing recomposition. This is called “conditional invalidation”.
- Requesting a screen frame from the Choreographer that otherwise wouldn't be needed.
- When the frame callback occurs:
- Asking the
derivedStateOfto recalculate its result with the new dependency values. - Seeing the old result and the new result are equivalent, and not recomposing anything after all.
- Asking the
But composables aren't the only things that can observe state. Layout and draw scopes have their own overhead when restarting unnecessarily. For example, when a drawBehind block is invalidated, Compose will not only run that drawBehind block again, but will also re-execute other draw modifier blocks that draw into the same graphics layer.
Now, the occasional unnecessary invalidation is usually pretty harmless. However, they tend to become much more noticeable when they happen on every frame of an animation, since just a little extra work can cause a frame to skip and break the illusion of smooth movement. One of the most salient examples of the real-world cost involves scrolling. Scroll gestures and animations are fairly efficient because they are tightly scoped. On each frame, the operation:
- Updates the float scroll offset state. This invalidates a
graphicsLayerscope somewhere that read the scroll offset state. - The graphics layer block is re-executed, applying the new offset, and the platform graphics rendering pipeline re-executes the already-recorded, low-level drawing instructions (the “displaylist”) from the content layer at the new offset, without needing to re-execute any user draw code (e.g.
drawBehind). This is a low-level graphics operation that is very fast.
Note that none of the composition, layout, or even draw phases are involved. Now, consider a composable that reads the ScrollState.value property, maybe to display some UI when the content is scrolled to a limit:
@Composable fun MyScrollable(
scrollState: ScrollState,
content: @Composable () -> Unit
) {
Box {
Box(Modifier.verticalScroll(scrollState)) {
content()
}
val isAtTop = scrollState.value == 0
if (!isAtTop) {
ScrollToTopButton(scrollState, Modifier.align(BottomEnd))
}
}
}This function only really cares when the scrollState.value becomes equal or unequal to 0—it does not care when it changes from 0.5 to 1, or any of the other virtually infinite values it can have. However, during a scroll operation, scrollState.value changes on every frame. Now instead of merely updating a graphics layer offset, the whole MyScrollable function has to be restarted, on every frame. Box is an inline function, so the entire body of MyScrollable will be re-executed, and the modifier elements for verticalScroll and align will be re-allocated just to be thrown out since they didn't change. Add a few more bits of UI to this composable, and the work starts to add up, making frame skips more likely.
We can use derivedStateOf to avoid recomposing until the scroll value actually changes:
@Composable fun MyScrollable(
scrollState: ScrollState,
content: @Composable () -> Unit
) {
Box {
Box(Modifier.verticalScroll(scrollState)) {
content()
}
// A different scrollState could be passed in, so it must be a key.
// We could also put it in a rememberUpdatedState.
val isAtTop = remember(scrollState) {
derivedStateOf { scrollState.value == 0 }
}
if (!isAtTop.value) {
ScrollToTopButton(scrollState, Modifier.align(BottomEnd))
}
}
}Now, on each scroll frame MyScrollable will be marked as conditionally invalidated, and before recomposing it will check the value of isAtTop, see that it hasn't changed, and not bother recomposing at all. Running scrollState.value == 0 is much cheaper than recomposing the entire MyScrollable function. There is still some overhead to derivedStateOf, but it's much less than recomposing.
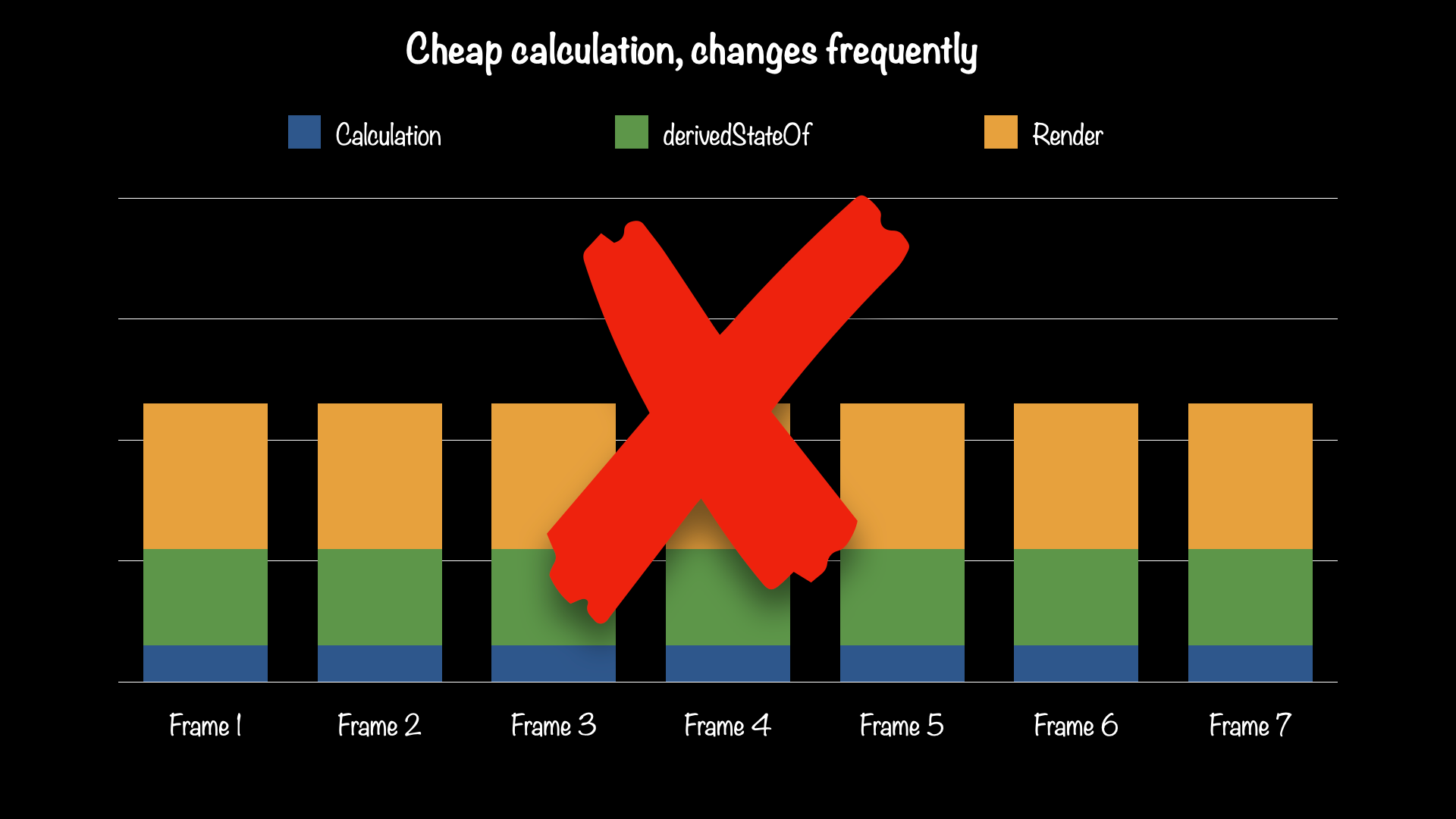
Here are some more unscientific charts to illustrate. The calculation, scrollState.value == 0, is relatively cheap. Rendering (in this case, recomposing) is relatively expensive, and the overhead of derivedStateOf is somewhere in between. It's not free, but by eliminating unnecessary recomposition from most frames, it is still better.
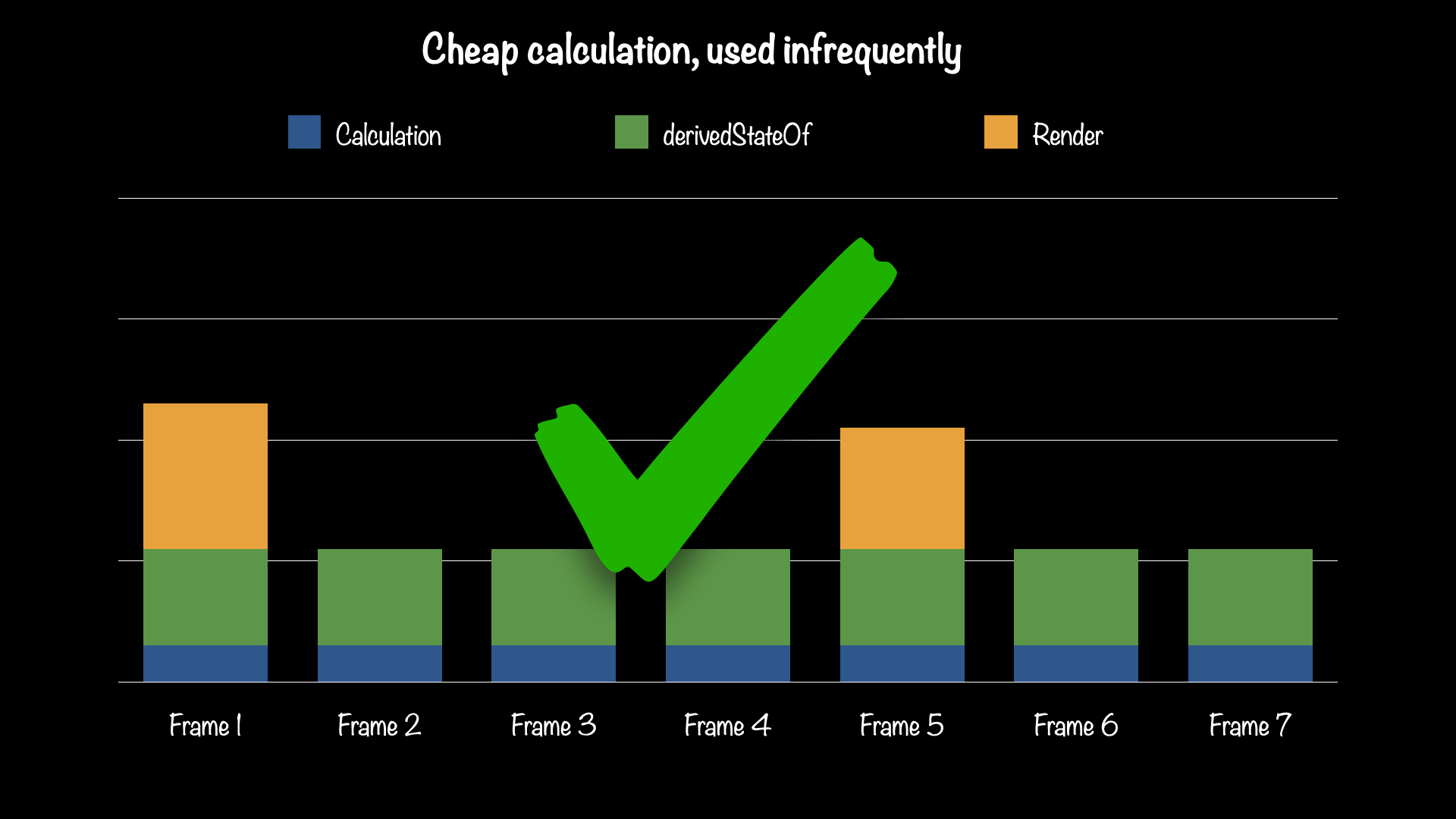
Left: derivedStateOf is not used. Right: derivedStateOf is used to prevent recompose/relayout/redraw on most frames.
Caching
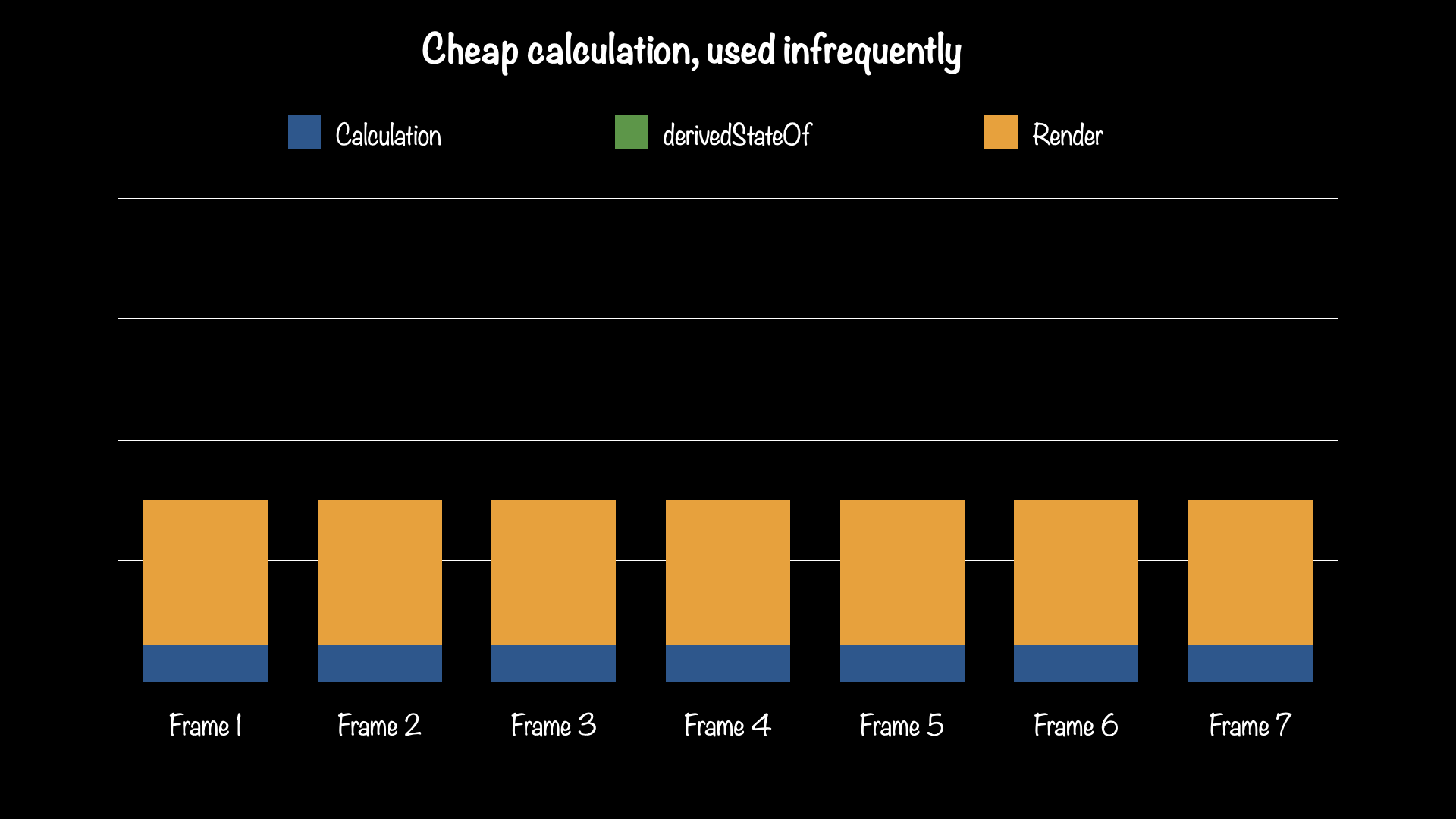
The other key feature of derivedStateOf is that it caches the result of its calculation, so when asked for its value multiple times, if none of its dependencies have changed, it doesn't even need to re-execute the calculation. In many cases derivedStateOf calculations are quite cheap, but may still do things like allocate objects just to immediately be made available for garbage collection, creating unnecessary memory management work.
When the result of a derivedStateOf is read frequently, but its dependencies don't change very often, the primary benefit comes from skipping the calculation altogether.
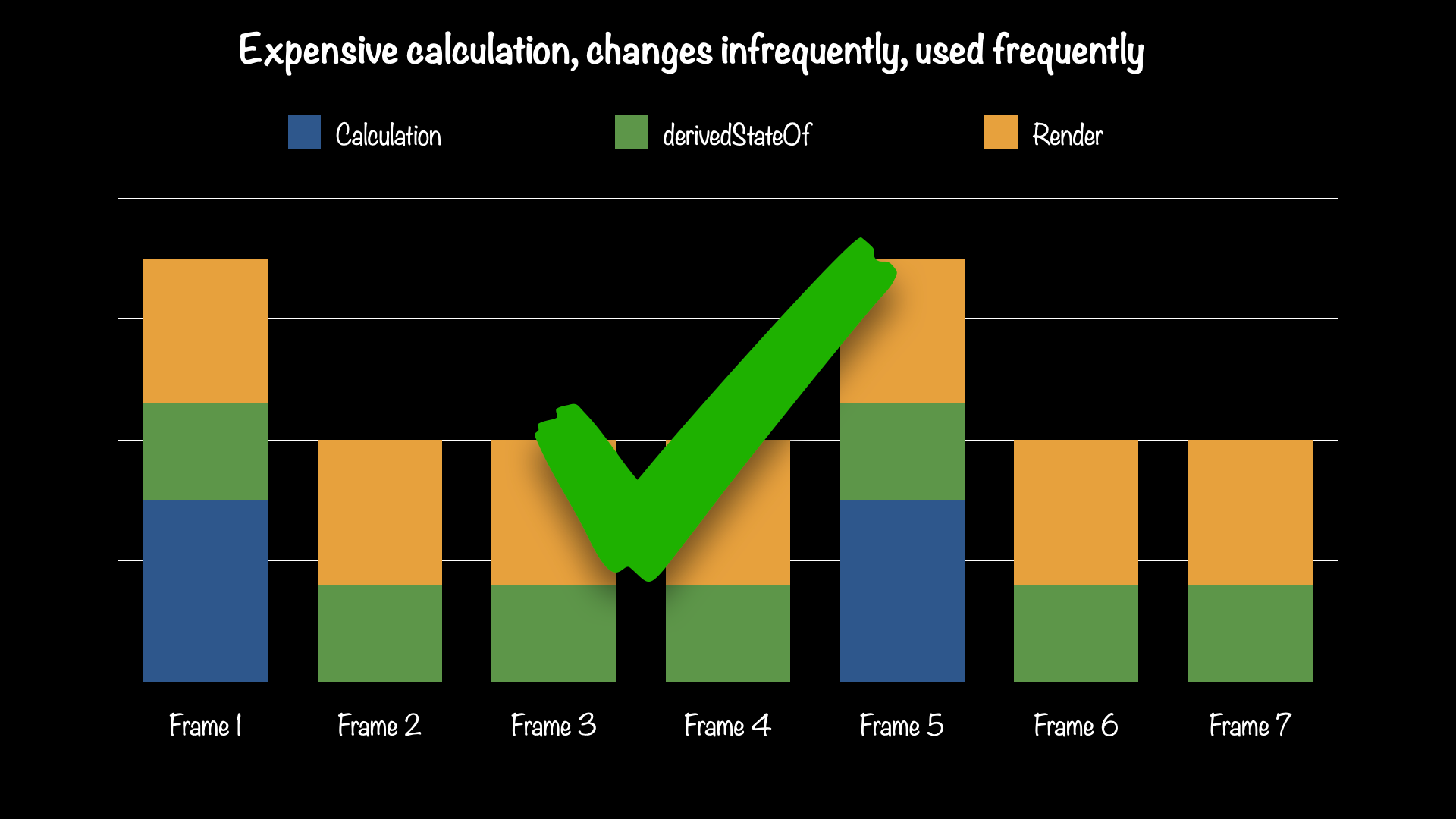
Left: derivedStateOf is not used. Right: derivedStateOf is used to avoid re-calculating on most frames.
Mechanics
derivedStateOf leverages the underlying mechanics of Compose's snapshot state system to do some cool tricks. It is very helpful to have at least a basic understanding of how snapshots and state objects work before trying to understand derivedStateOf, so if you need a refresher on that I would recommend watching Opening the shutter on snapshots before continuing.
How derivedStateOf avoids invalidating
Consider a derivedStateOf whose calculation function reads n state objects. Its calculation will report n+1 reads: The derivedStateOf object reports the read of itself first, and then reports each of its dependencies.
Unlike most state objects, derivedStateOf doesn't use readable and instead invokes the read observer directly (source):
override val value: T
get() {
// Unlike most state objects, the record list of a derived state can change during a
// read
// because reading updates the cache. To account for this, instead of calling readable,
// which sends the read notification, the read observer is notified directly and current
// value is used instead which doesn't notify. This allow the read observer to read the
// value and only update the cache once.
Snapshot.current.readObserver?.invoke(this)
…When the read misses the cache, the calculation function needs to be executed, and simply running the calculation function causes each of the dependency state objects to be reported. On a cache hit, the calculation function isn't executed, but the dependencies still need to be reported as reads, so the naive observer will know it needs to watch those objects for changes. So it reports them itself, without actually reading them again (source):
// If the dependency is not recalculated, emulate nested state reads
// for correct invalidation later
val dependencies = readable.dependencies
…
dependencies.forEach { dependency, nestedLevel ->
…
snapshot.readObserver?.invoke(dependency)
}This means any time a read observer reads a derivedStateOf, it will see all state reads reported as though the calculation were re-executed every time, even though it might not actually execute. A naive read observer will end up watching all the dependencies for changes and invalidate itself whenever a dependency changes. It will also notice when the cached result of the derivedStateOf changes, although that can't happen without a dependency changing, so tracking the derivedStateOf itself is redundant.
This is why more advanced observers, such as SnapshotStateObserver and composition, will not record derivedStateOf reads like other state reads. It tracks those derived states' dependencies and values, and only invalidates when a write to a dependency causes the value of the derived state to change. This requires more bookkeeping than you might expect.
Nested state reads
Because derivedStateOf calculations read other states, which may be derivedStateOf objects themselves, derived state reads form trees. Any time a derivedStateOf is going to read, or reports reads of, its dependencies, it uses an internal observer mechanism to notify potential observers that nested reads are about to occur. An internal DerivedStateObserver interface has start and stop callbacks that get passed the current derivedStateOf, and code in the Compose runtime module can use a scope function to register an observer for a block of code (source). In SnapshotStateObserver, the listener tracks the depth of state reads by incrementing a counter on start and decrementing it on stop (observer, registration). When the SnapshotStateObserver gets notified about a state read, it checks this depth counter and returns early for all nested reads. This saves work because the read observer code only runs once for each top-level state read. However, when that state is a derivedStateOf, it does still track dependencies, but does so using a different technique (source).
Dependency tracking
When a derivedStateOf runs its calculation function, it installs its own read observer to track dependencies (source):
val newDependencies = MutableObjectIntMap<StateObject>()
val result = withCalculationNestedLevel { calculationLevelRef ->
…
Snapshot.observe(
{
if (it === this) error("A derived state calculation cannot read itself")
if (it is StateObject) {
…
newDependencies[it] =
min(
readNestedLevel - nestedCalculationLevel,
newDependencies.getOrDefault(it, Int.MAX_VALUE)
)
}
},
null,
calculation
)
…Note that this tracks transitive dependencies too. Each derivedStateOf tracks all its dependencies, even those of nested derived states.
After the calculation returns, it saves the list of dependencies in its state record. When a SnapshotStateObserver sees a derived state read, it gets the current state record (which will also perform the calculation if it's stale) and asks it directly for that dependency list (source).
if (value is DerivedState<*> && previousToken != currentToken) {
val record = value.currentRecord
// re-read the value before removing dependencies, in case the new value wasn't read
recordedDerivedStateValues[value] = record.currentValue
val dependencies = record.dependencies
val dependencyToDerivedStates = dependencyToDerivedStates
dependencyToDerivedStates.removeScope(value)
dependencies.forEachKey { dependency ->
if (dependency is StateObjectImpl) {
dependency.recordReadIn(ReaderKind.SnapshotStateObserver)
}
dependencyToDerivedStates.add(dependency, value)
}
}It then not only tracks each of those dependencies as state objects to watch for changes, but also stores a mapping from each of the dependencies back to the derivedStateOf that read it. A single state object may be read by multiple derived states, so this mapping is one-to-many. When the SnapshotStateObserver's apply observer detects that a dependency was written to, it uses this mapping to find the derivedStateOf that read it, and then which scopes read that derivedStateOf. Nested derived states are supported because, as I mentioned above, every derived state tracks its transitive dependencies too.
ReaderKind.SnapshotStateObserver is used to optimize write tracking for different types of observers. See here.In addition to tracking its dependencies, SnapshotStateObserver also tracks each derived state's value. This is, finally, where the actual deduping of invalidations happens: When a SnapshotStateObserver determines that a changed state object was only read as a dependency of a derived state, it will ask that derived state for its latest value and doesn't invalidate the scope that read it unless the value actually changed.
The state observation logic for composable functions is a little more distributed, but mostly works in the same way. When a derived state's dependency was written to, but it has not yet been determined if the calculation result is different, the composable is conditionally invalidated. One notable optimization composition's observer adds is that when a composable has been conditionally invalidated and then gets a state object that was read directly gets changed, it drops the conditional invalidation tracking state since it no longer matters. In both cases, derivedStateOf only reduces invalidations by coordinating with the state observer, it can't do it on its own.
You might already be starting to realize how much extra work and internal state is required to handle derivedStateOf compared to other state objects, and why it's not worth using for calculations that change as frequently as their dependencies.
How derivedStateOf avoids recalculating
A typical state object is only asked for its value by the code reading it. The read observer only tracks that the object was read or written to, and never actually looks at or cares about the actual value of the state object. In contrast, note how often a particular derivedStateOf object's calculation result is requested in the above SnapshotStateObserver logic:
- By the code actually reading the derived state.
- In the read observer, which gets the value to compare later.
- In the apply observer, which gets the value to compare with the previous one.
- Each time a derived state that read another derived state needs to check if its cache is stale.
Also consider that a derivedStateOf's value is not just a data lookup but involves some computation, and also reading one or more other state objects. If a reading a normal state object takes s time, then reading a derived state that reads n state objects takes at least s+3sn time, or more if nested derived states are involved: s for the derived state itself, and 3sn for its calculation. If it actually performed the calculation each time, that would be very expensive. Note this is only inside a SnapshotStateObserver or composable, naive read observers will read the derived state fewer times but will also invalidate more.
For this reason, and also just because a derived state can be read multiple times by completely different code paths, the result of the calculation is cached in the derived state's StateRecord.
Caching fundamentals
In order for any cache to be effective, determining if a value is stale or not must be quicker than actually computing the value again. Web caches, for example, use the address of a page as the key into something like a hash map, and determine if a cached page is stale by compare various timestamps that are specified by the page to the current time (it's a bit more complicated in practice, but that's the basic idea).
In Compose, we don't have URLs or timestamps. The derivedStateOf object itself stores the cached value, so we don't need anything like a URL to act as a key. To determine whether the cache is stale, we need to know if the dependencies have changed since the last time we checked. If the calculation function is “pure”, then its result is only a function of other snapshot state objects and possibly some constant values. If we have a way to determine that none of the dependency state objects have changed, then we can deduce that the result cannot possibly have changed.
Well, the most obvious way to tell if the dependencies changed would be to store each of their values and compare to the new values. But remember, we're dealing with arbitrary state objects here. Something like MutableState has a nice simple value we could store, but what value would we store for SnapshotStateList? We'd have to make a copy of the whole list. Furthermore, anyone can define a state object, which the cache could not possibly know how to copy. And even for MutableState, the value could be something that is not cheap to compare, like a java.net.URL, or a long AnnotatedString with tons of annotations. Luckily, the snapshot system has some nifty properties we can use to compare state objects without actually knowing what data they hold.
Snapshot IDs for fun and profit
Snapshots are identified by monotonically increasing integer IDs. Every time you create a new snapshot, it gets the next-highest ID. Each state object can store multiple versions of its data in records, where each record is tagged with the ID of the snapshot that wrote it. Generally, a state record can only be written to by a single snapshot: when you write to a state object, it looks for the record with the current snapshot's ID, and creates a new one if necessary (or re-initializes an unused one). When you read a state object, it looks for the record with the highest ID equal to or less than the current snapshot ID. This is how you can see different values for the same state object when reading it from different snapshots. I explain this in more detail in Opening the shutter on snapshots.
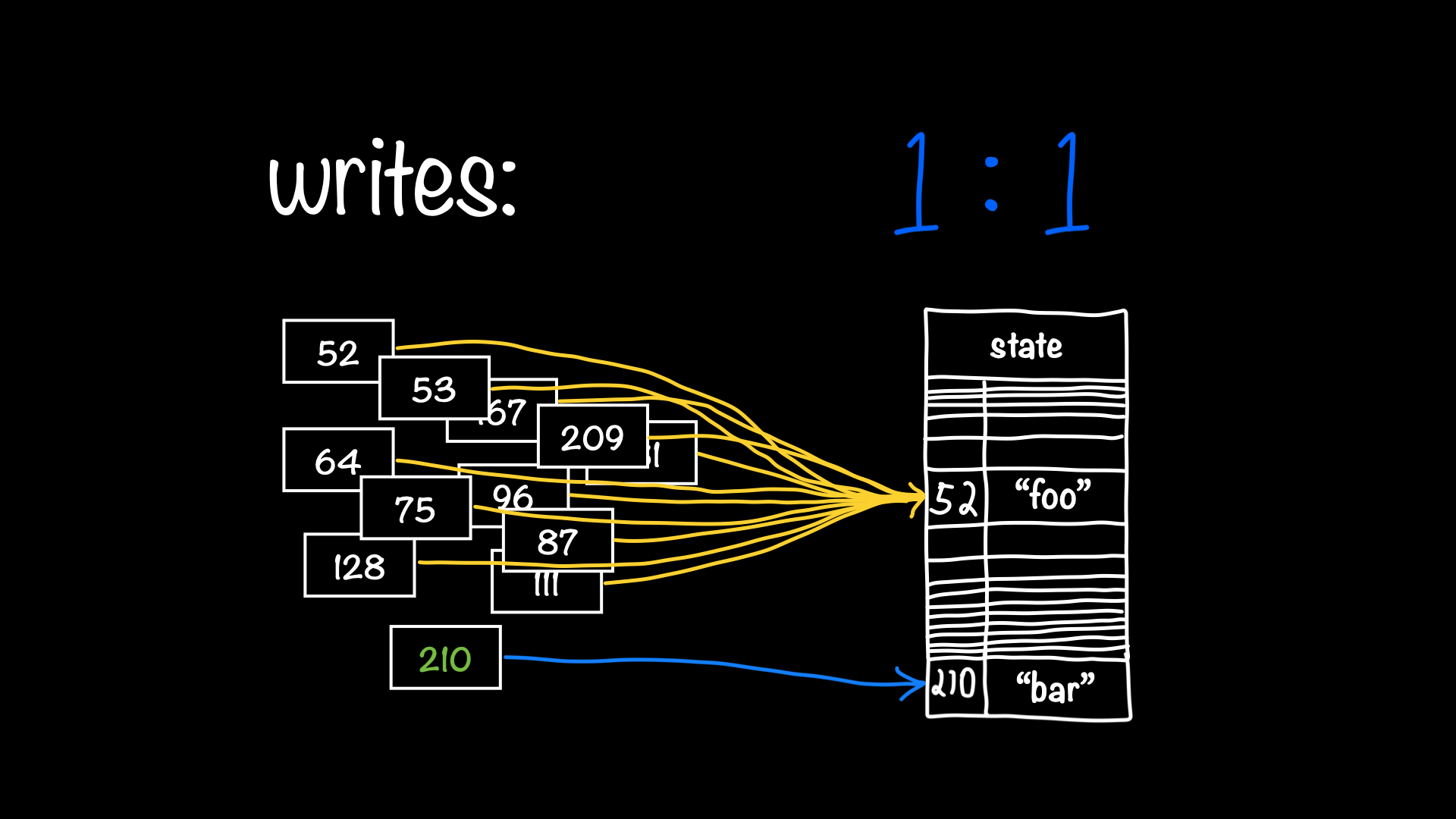
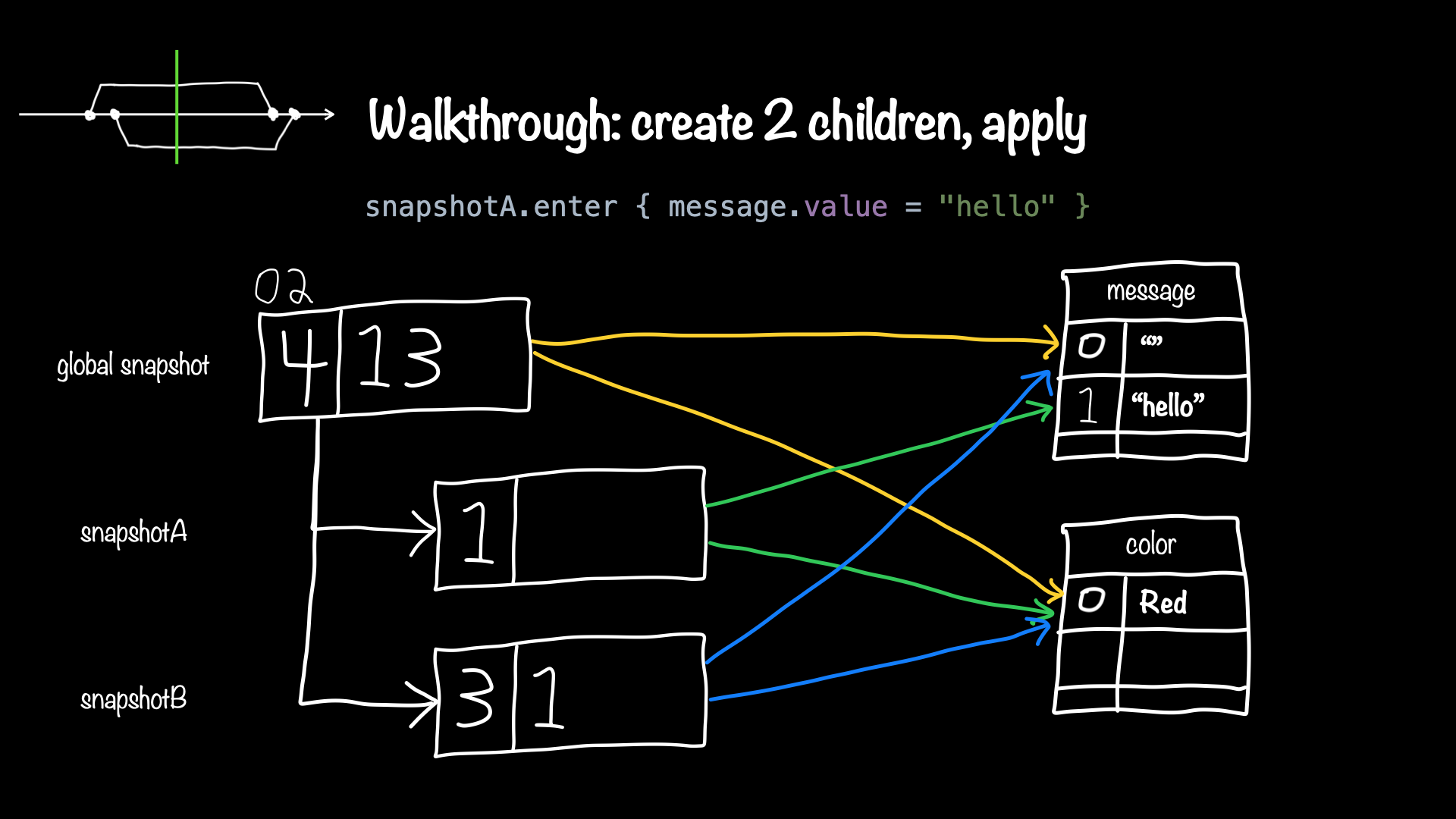
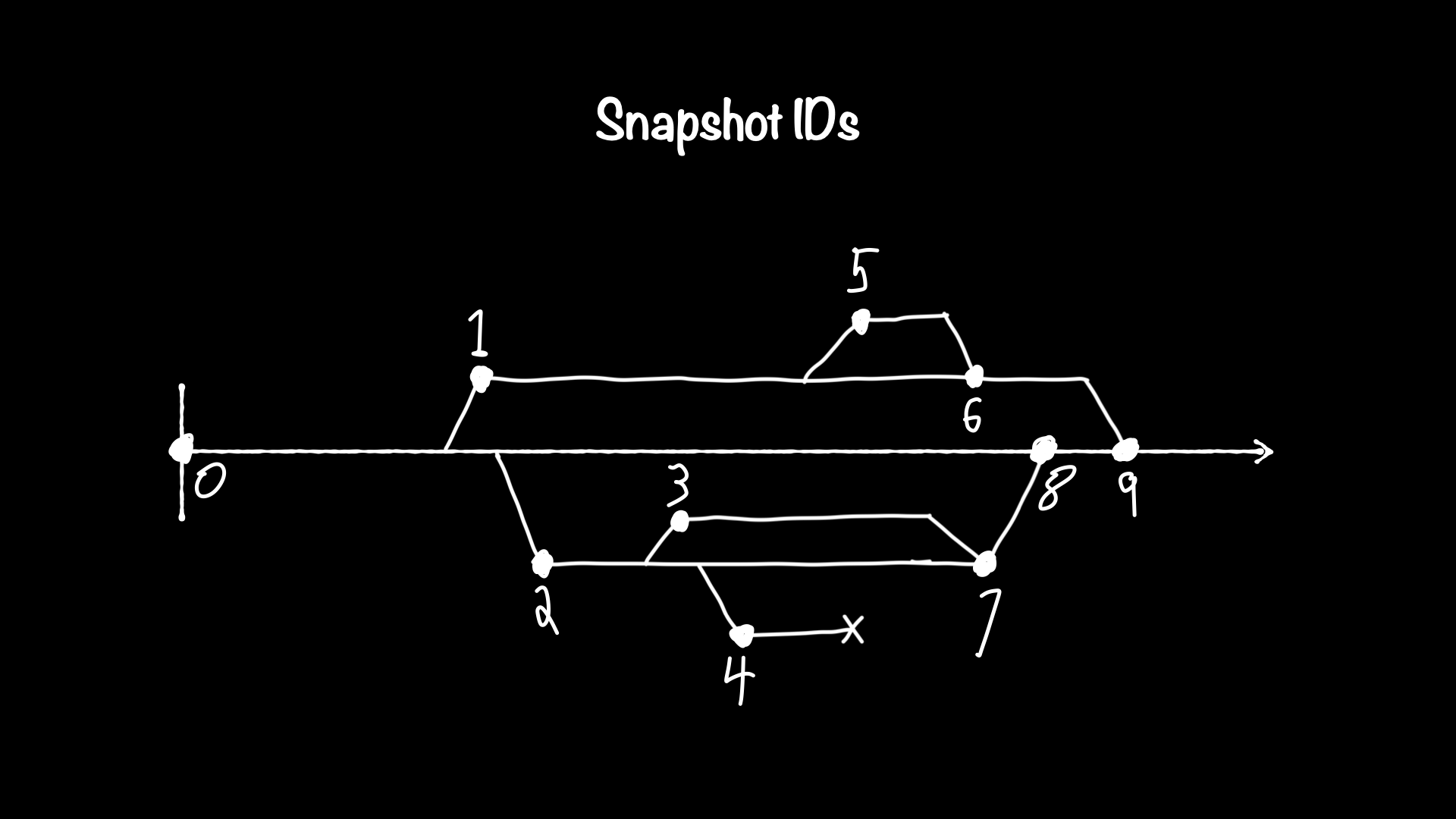
Some highlights from my talk Opening the shutter on snapshots.
Since snapshot IDs are never re-used, and state records always have the ID of the snapshot that wrote them, we can compare the snapshot IDs of the currently-readable record of a particular state object to tell when it's been written. If we are in snapshot with ID 6 and read a state object where the current record has ID 5, then we know the object was last written to in a previous snapshot. If we later read it and the current record is still ID 5, that means that nothing has written to the state object since we last read it (from the perspective of the current snapshot). If it has a different ID, then we know something wrote to it, but we can't know if it has a different value. Many state objects will ignore writes when the new value is equivalent to the current value, so for the purposes of caching derivedStateOf values, comparing the snapshot IDs of dependencies' records is a good enough proxy for determining whether they've changed.
Ok, well it's almost good enough. There's one edge case where we can't rely on record IDs: writes in the current snapshot. Consider the following code:
val state = mutableStateOf(0)
val derived = derivedStateOf { state }
Snapshot.withMutableSnapshot {
// Current snapshot has ID 5.
// Creates a new state record with ID 5.
state.value = 1
// Reads state, sees record ID is 5.
println(derived.value)
// Still in same snapshot, so writes to
// the same record, with ID 5.
state.value = 2
// Reads state again, sees record ID is still 5,
// even though it has a new value.
println(derived.value)
}So we need a way to tell if the current snapshot has changed. To do this, we track two values: the ID of the snapshot that the cache was last valid in, and the write count of the snapshot at that time. The write count is a value stored in the snapshot that is incremented every time a state write is performed. Also, any time a derivedStateOf is read and runs the calculation function, it “advances” the current snapshot—essentially meaning it moves the current snapshot's ID to the next available one (source). Any subsequent writes to any state objects will then be forced to use a new record with the new ID, and the next time the derived state is read it will see a different record ID. Here's the same code snippet with this new behavior:
val state = mutableStateOf(0)
val derived = derivedStateOf { state }
Snapshot.withMutableSnapshot {
// Current snapshot has ID 5.
// Creates a new state record with ID 5.
state.value = 1
// Reads state, sees record ID is 5, then advances snapshot.
println(derived.value)
// Current snapshot now has ID 6.
// Creates a new state record with ID 6.
state.value = 2
// Reads state again, sees record ID is 6, so re-calculates.
println(derived.value)
}The reason we track both snapshot ID and write count is to handle nested reads:
Snapshot.withMutableSnapshot {
val state = mutableIntStateOf(0)
val derived = derivedStateOf { state }
val nested = derivedStateOf {
derived.value // 0, doesn't advance snapshot because nested
state.value++
derived.value // 1, still the same snapshot id
}
}
These values enable another optimization: The ID and write count are stored in the derivedStateOf, and if they're the same on the next read, it means nothing has changed and the cache is still valid.
Now that we've seen what data is used by the cache, let's look at how derivedStateOf uses all this data to implement the cache.
The caching algorithm
Using all these snapshot IDs, we can now come up with an algorithm to detect whether the cache is stale (re-calculation needed) or valid (no need to re-calculate). When the derived state is read, its cached value is valid if:
- There even is a cached value (the cache is initialized lazily). If there's no cache value, this is the first time it's being read and needs to be calculated.
- If there is some value in the cache: The cached snapshot ID is the same as the current snapshot ID and the current snapshot's write count is the same as the cached write count. If the IDs and write counts are the same, none of the dependencies can possibly have been written to since the last read, and we can just return the cached value.
- If the snapshot or write count are different: All the dependencies' records' cached IDs are the same as their current record IDs. If the IDs are all the same, then none of the dependencies can possibly have been written to since the last read, and we can just return the cached value.
- Note that this check only includes direct dependencies, not nested dependencies. This works because
derivedStateOfalways uses a fresh record when its calculation result changes.
- Note that this check only includes direct dependencies, not nested dependencies. This works because
If the last condition succeeds, meaning none of the dependencies were written to, then it means next time the derived state is read we can exit early, at step (2), as long as we're in the same snapshot. So before returning the cached value, we update the cached snapshot ID to the current ID. So far, all we're doing is integer comparisons. It doesn't matter what values the dependencies actually contain, all the cache needs to do in most cases is compare some int values. The logic up to this point is implemented in the isValid function:
fun isValid(derivedState: DerivedState<*>, snapshot: Snapshot): Boolean {
val snapshotChanged = sync {
validSnapshotId != snapshot.id || validSnapshotWriteCount != snapshot.writeCount
}
val isValid =
result !== Unset &&
(!snapshotChanged || resultHash == readableHash(derivedState, snapshot))
if (isValid && snapshotChanged) {
sync {
validSnapshotId = snapshot.id
validSnapshotWriteCount = snapshot.writeCount
}
}
return isValid
}Don't worry about resultHash and readableHash for now, I'll explain them in a bit.
If the last condition fails, it means at least one of the dependencies was written to since the last read, the calculation might produce a different result, and so we need to re-execute the calculation function. As I mentioned earlier, most state objects won't even perform a write unless they're getting a new value, so there's a pretty good chance a dependency actually changed.
As we re-execute the calculation, we use a read observer to track updates to our dependency set. In many cases the calculation will read the exact same state objects again, but it is possible for there to be different dependencies if the calculation has a branch. In that case, the branch must itself be based on a state object.
derivedStateOf {
if (state1.value) {
state2.value
} else {
state3.value
}
}This dependency set will either be {state1, state2} or {state1, state3}.
Once the calculation returns a result, we compare it to the cached result. The comparison is done using the optional SnapshotMutationPolicy passed to derivedStateOf. If no policy is passed, then the default policy depends on where the state is read:
- When read in composition or a
SnapshotStateObserver, the policy defaults tostructuralEqualityPolicy(), which compares values by calling theequals()method. - Anywhere else (including when read in another derived state calculation), the policy defaults to
neverEqualPolicy().
derivedStateOf, always consider passing an explicit policy parameter to avoid invalidating when the calculation result doesn't change.In most cases you can probably pass
structuralEqualityPolicy() (which is also the default for mutableStateOf).If the policy determines that the values are equivalent, then the new dependency set is stored in the cache as well as the dependencies' record IDs, so we exit early at step (3) next time. The snapshot is advanced, and then the current snapshot ID is stored in the cache as well so we can exit even earlier at step (2). Finally, the result is returned. (source)
val newDependencies = MutableObjectIntMap<StateObject>()
val result = …
val record = sync {
val currentSnapshot = Snapshot.current
if (
readable.result !== ResultRecord.Unset &&
policy?.equivalent(result, readable.result as T) == true
) {
readable.dependencies = newDependencies
readable.resultHash = readable.readableHash(this, currentSnapshot)
readable
}
…
}
…
// Advance the snapshot.
Snapshot.notifyObjectsInitialized()
sync {
val currentSnapshot = Snapshot.current
record.validSnapshotId = currentSnapshot.id
record.validSnapshotWriteCount = currentSnapshot.writeCount
}
…
return recordHowever, if the calculation produces a new result—either because it's the first time being ran (step (1) failed), or because it's different than the cached value or there's no mutation policy—then we create a new writeable record and write all the new cache metadata, including the result, into that record. (source)
if (
readable.result !== ResultRecord.Unset &&
policy?.equivalent(result, readable.result as T) == true
) {
…
} else {
val writable = first.newWritableRecord(this, currentSnapshot)
writable.dependencies = newDependencies
writable.resultHash = writable.readableHash(this, currentSnapshot)
writable.result = result
writable
}Once a record is initialized, the result property will never change. Whenever a derivedStateOf calculates a new result, it always writes that into a fresh state record. This allows the trick of using record IDs as a proxy to detect changes to work transitively. If a derived state's calculation reads another derived state, it can still use the nested derived state's record IDs to determine if it has changed and the outer calculation needs to be re-executed.
Lastly, let's discuss how this data is actually stored in the state object, and talk about one more trick derivedStateOf uses.
Storing the cache
As we've already discussed, derivedStateOf is a state object. It subclasses StateObject and stores its data in a list of StateRecords. Its state record holds the following data (source):
var validSnapshotId: Int = 0
var validSnapshotWriteCount: Int = 0
override var dependencies: ObjectIntMap<StateObject> = emptyObjectIntMap()
var result: Any? = Unset
var resultHash: Int = 0We've already talked about most of these:
validSnapshotIdis the ID of the snapshot the last time the derived state was read.validSnapshotWriteCountis the write count from the last time the derived state was read.dependenciesis a map of the dependency state objects to the nesting level at which they were read (remember,derivedStateOftracks all its transitive dependencies, not just its immediate ones).- Notably, this does not contain the dependency record IDs.
resultis the last calculation result. This is the only publicly visible property.resultHashis how the dependency record IDs are tracked.
Earlier, I said the cache stores the last-read record ID for each dependency. Well, I lied. It doesn't store the actual IDs, it just hashes all the IDs together along with their records (the hashcodes of the actual StateRecord objects). This takes much less memory than actually storing the IDs in a list or map and still achieves the same goal. Here's the actual code that calculates the hash (source):
fun readableHash(derivedState: DerivedState<*>, snapshot: Snapshot): Int {
var hash = 7
val dependencies = sync { dependencies }
if (dependencies.isNotEmpty()) {
notifyObservers(derivedState) {
dependencies.forEach { stateObject, readLevel ->
if (readLevel != 1) {
return@forEach
}
// Find the first record without triggering an observer read.
val record =
if (stateObject is DerivedSnapshotState<*>) {
// eagerly access the parent derived states without recording the
// read
// that way we can be sure derived states in deps were recalculated,
// and are updated to the last values
stateObject.current(snapshot)
} else {
current(stateObject.firstStateRecord, snapshot)
}
hash = 31 * hash + identityHashCode(record)
hash = 31 * hash + record.snapshotId
}
}
}
return hash
}By including both the records and their IDs in the hash, this handles both the case where a dependency is replaced with another dependency with the same record ID, and the case where a dependency's state record gets reused with a newer ID. This does theoretically mean a dependency change could happen that produces the same hash value and the derived state could incorrectly determine the cache is valid when it's actually stale, but the chance of this happening is low enough that it's not a concern.
I mentioned earlier that we only create a new writeable record when the result property needs to be written. This obeys the StateObject contract: any time data is written in a new snapshot, it must be written to a fresh record. However, this record class contains other properties that also need updating at separate times. As shown in the above code snippets, whenever the cache needs to update metadata without saving a new result, it just… writes directly into the state object. It gets a readable record, and mutates it! 😱 This is not allowed!
The reason it's not (publicly) allowed is because the overall snapshots algorithm requires all record writes to be done in a global lock: the sync function shown in the above snippets. That's right, every time you write to a state object, you're briefly holding a global lock. Well-behaved state objects do nothing inside this critical section other than update some record fields, which is very fast, so in practice contention on this lock is quite low. This lock is also an implementation detail of the snapshot system, so no external code can acquire it (except by calling writeable). If you look at DerivedState.kt, you'll notice that any time the derived state record is updated, it's done inside one of these sync blocks. derivedStateOf can only do this because it lives in the same module as the rest of the snapshot code. Updating the current record without creating a new writeable one just for cache metadata updates is otherwise fine because none of the metadata is exposed publicly and so from the outside derivedStateOf behaves just like any state object is expected to. However, because it's updating a record obtained from readable, it means multiple snapshots might be accessing the same record concurrently. This is the whole reason why writing should always be done into a separate record, but it's ok for derivedStateOf because (1) the writes are guarded by that lock and so there aren't actual data races, and (2) the cache metadata is just an optimization. If a derivedStateOf updates its metadata in one snapshot in one thread, and then another thread with a different snapshot immediately overwrites the metadata, the next time the first snapshot does a read it may determine that the cache is stale when it's really valid, but all that means is it's doing a little extra work. The cache behavior is still correct. This contention on a single derivedStateOf is also a rare enough occurrence that the extra work doesn't have a significant impact on general performance.
Conclusion
derivedStateOf is pretty complex, eh? All this work, just to save some invalidations. But it's worth it—as long as you're actually saving invalidations, because your outputs don't change as often as your inputs. derivedStateOf only runs the calculation function when it absolutely needs to, and determines that by quickly comparing snapshot IDs, not full object values. Composable functions and most other restartable functions, using SnapshotStateObserver, use the cached result to skip invalidating whenever possible.
Now that you've made it this far, why not take a look at DerivedState.kt—it's not a huge file, and just by reading this article you've already seen most of the code.
If you still have questions, check out my talk Deriving derived state: derivedStateOf explained. It covers the same content, but approaches it from a slightly different angle with a lot more diagrams and walkthroughs runtime mechanics.
Zach KlippensteinAlso, check out my other articles about Compose state.
Thanks to Andrei Shikov, Chuck Jazdzewski, and Nader Jawad for reviewing this post!