Implementing snapshot-aware data structures

Up to this point in this blog series, I've discussed how to use Compose's snapshot state system, some advantages of how it's designed, and the occasional best practice. But I haven't talked about where the rubber meets the road: how does something like mutableStateOf actually work? How can a single state object expose multiple different values to different snapshots at the same time? And maybe you don't care – which is fine – these details are not at all necessary to use Compose even for many advanced use cases, and you can have a whole successful career as a Compose developer without knowing any of it. It's just really, really cool.
I didn't completely understand this stuff myself until recently, when I spent a hackweek trying to make a moderately complex data structure snapshot-aware. The underlying algorithm, multi-version concurrency control or MVCC, has been around for a long time and lives in most database systems you've heard about. But most of us aren't implementing MySQL and don't want to read a bunch of academic papers just to figure out how your button color is actually changing. So in this post, I'm going to try to explain how the snapshot system actually works from first principles, and in the process maybe we'll accidentally learn something about MVCC too. If you'd like more algorithm content, or would just rather "watch" than "read", check out my talk Opening the Shutter on Snapshots.
Disclaimer: The snapshot system is subtle and elegant, and while it's not particularly complex, a lot of sophisticated behavior is implied by a small number of core mechanics. Instead of introducing the whole system all at once and then trying to explain how it all works together, I'm going to gradually build on ideas that are hopefully more obvious, glossing over some details and technicalities at first, but eventually ending up at the final product.
Some definitions
State
In this post, I will often talk about "state". State is any value or values that exist at a point in time. State can be read, and it can be changed. In practice, in Kotlin, state is something in a variable or property. Here are some examples:
// Top-level properties are state.
var globalCounter = 0
class LocalCounter {
// Class properties are state.
var count = 0
}
fun sum(items: List<Int>): Int {
// Local variables are state.
var sum = 0
for (item in items) sum += item
return sum
}
// Container types, like mutable lists, hold state,
// since the contents of the list can change over time.
val scores = mutableListOf<Int>()
State object
In this post, I'll use the term "snapshot state object", or "state object", as shorthand to mean "an object that holds some state that interacts with the Compose snapshot system". MutableState and SnapshotStateList are examples of this kind of state object. As you'll see later, there's also an actual StateObject interface, but when referring to that specific type I'll write StateObject.
A snapshot amuse-bouche
You can't talk about snapshot state without talking about snapshots, so let's review some key concepts. If you've just read the other posts in this series, feel free to skip this section.
Snapshots provide a few key features. They allow parts of a program to:
- Observe when changes are made to states they care about.
- Operate with the guarantee that any state they're reading won't be changed out from under them by another thread (as long as each thread uses its own snapshot).
- Ensure that changes they make to multiple states are visible to the rest of the program all at once.
A lot of the other posts in this series have been about that first point – observability. This is the feature that allows Compose code to be reactive without explicit stream or callback APIs. But the way observability works under the hood is actually, well, just not very interesting: Every snapshot can register a callback for any time a state object is read or written, and the state object code (which I'll discuss in a bit) simply sends the current state object instance to those callbacks when it's asked to read or write its value. So just like with any other fancy observability/reactive library, it's ultimately just some abstractions around callbacks.
This post is more concerned with the second two points. Snapshots are like database transactions: you open a snapshot (take(Mutable)Snapshot), read and write data inside it, and then either commit it (apply) or dispose it without committing (no explicit call, just dispose without applying it). There’s an acronym that’s commonly used to describe this set of features in the database world: "ACID". The letters stand for Atomicity, Consistency, Isolation, and Durability. Compose’s snapshot system supports the first three:
- Atomicity: Changes to state inside a snapshot are not visible to any other snapshots until the snapshot is applied, and when that happens, all the snapshot's changes are visible to other snapshots at once.
- Consistency: As soon as a snapshot is created, the values of all state objects will continue to have whatever value they had when the snapshot is created for code running inside the snapshot – even if the values are immediately changed outside the snapshot. Also, if two snapshots try to change the same state objects in an incompatible way, then the first snapshot to be applied will succeed, but the
applycall for the second snapshot will fail. - Isolation: No changes made to any state object inside a snapshot will be visible to any other snapshots until it's applied, and no changes made outside a snapshot will be visible inside the snapshot. Note that snapshots only guarantee isolation between snapshots, not between threads. It's possible for multiple threads to see the same snapshot simultaneously, most commonly with the global snapshot. For this reason, it's best to always ensure that anything operating on snapshot state in a background thread is doing so in a snapshot specific to that thread (e.g. via
Snapshot.withMutableSnapshot).
Snapshots don't provide durability because they only operate with in-memory state.
The way the snapshot system achieves all this is by using multi-version concurrency control. There are two parts to Compose's implementation of MVCC: snapshots themselves (the Snapshot class), and objects that store application state (the StateObject interface). The former probably deserves a dedicated blog post, which I will definitely make a note to write, but for now I'll just focus on the latter. I think, personally, that it's just really interesting to understand how this works, but it might also be helpful to know if you ever find yourself in a situation where the existing state objects aren't quite the right fit for a problem. I'll talk about when that might actually happen at the end of the post.
What makes a "state object"?
Let's zoom out from Compose APIs for a bit and talk about something more fundamental: storing mutable data.
State records: storing mutable data indirectly
Consider how you typically write a mutable class. Let's write one to store the weather:
class Weather(temp: Int, humidity: Float) {
var temp: Int = temp
var humidity: Float = humidity
}
This class stores each of its two components as regular properties, backed by fields, on the class. But let's make it more fancy, just for fun. We can move all the properties into an internal class, and give the public class a single property that stores an instance of the private class holding all the actual data. We'll call this internal class a "record" – it holds a record of what the contents of this object are at a certain point in time. If this seems a bit silly and arbitrary, just bear with me, because this will let us do some neat tricks in a minute.
class Weather(temp: Int, humidity: Float) {
private val record = Record(temp, humidity)
var temp: Int
get() = record.temp
set(value) {
record.temp = value
}
var humidity: Float
get() = record.humidity
set(value) {
record.humidity = value
}
private class Record(
var temp: Int,
var humidity: Float
)
}
Great… all we've done is push our properties down into another class. But now that all our data is in a separate class, we can keep different versions of state internally.
Versioning records
We can keep track of all the changes to a single Weather instance by storing a list of records, instead of only the current record. Any time we read or write, we look at the last record in the list. Anytime we want to remember what the value was at the current time, we just push a new copy of the record onto the list, and save the index of the record we want to remember. This index represents a "snapshot", if you will, of the value of the state object at a point in time. Here's how this could be implemented:
class Weather(temp: Int, humidity: Float) {
private val records = mutableListOf(Record(temp, humidity))
private var currentRecordIndex = 0
private val currentRecord
get() = records[currentRecordIndex]
// These mutators will now automatically reference
// whatever record currentRecordIndex points to.
var temp: Int
get() = currentRecord.temp
set(value) {
currentRecord.temp = value
}
var humidity: Float
get() = currentRecord.humidity
set(value) {
currentRecord.humidity = value
}
// Takes a new snapshot and returns an ID that can be
// passed to restoreSnapshot.
fun takeSnapshot(): Int {
// The snapshot ID is the index of the current
// record – any writes after this method returns
// will use a new record.
val id = currentRecordIndex
// Push a copy of the current record onto the record
// list and update the snapshot ID to the index of
// that new record, so any subsequent writes will
// use the new record.
records += currentRecord.copy()
currentRecordIndex = records.lastIndex
return id
}
// All we have to do to change the record we're
// currently looking at is set the index.
fun restoreSnapshot(id: Int) {
currentRecordIndex = id
}
private data class Record(
var temp: Int,
var humidity: Float
)
}
Yikes, who knew the weather could be so complicated? Let's analyze this piece-by-piece to make sure we understand exactly what is going on. The Weather class now has two responsibilities:
- It stores and provides read/write access to the weather data, and
- It lets you create snapshots of the weather data at any point and select which snapshot you want to view or update.
Reading and writing to a Weather object works almost the same as before: we look up the record for the current record index, then mutate that record in-place. Looking up the current record is a constant-time operation, and a very fast one at that, so reads and writes don't have much overhead.
Taking a snapshot is the most complicated operation so far. To save the current values, we need to remember the index of the current record in the list. But we also need to make sure that any writes that happen after the snapshot is taken don't modify the snapshotted values. To avoid changing them, we make a copy of the current record and add it to the list. Copying the record means any reads after the snapshot is taken will see the same values as before, but that any writes will be isolated from the snapshot. Lastly, we need to update the current record index to "activate" the new record. Taking a snapshot is the most expensive operation too, since it requires copying a Record object and adding it to a list.
Restoring a snapshot, on the other hand, is super cheap, since it's just updating the index. Note that after restoring a snapshot, any writes will update that snapshot in-place.
So aside from a slightly clunky API, have we done it? Have we built our own implementation of Compose's snapshot system? Not quite.
Snapshot records
Our Weather class only supports snapshots of a single class, and they don't have all the features of Compose's snapshots. We're still quite far from a complete MVCC implementation – as I said at the beginning of this post, a full explanation of MVCC deserves its own post. But while there are a few differences, the core idea of using a list of records associated with individual snapshot IDs is exactly how Compose's snapshot state system works.
| Weather | Compose |
|---|---|
| In both cases, the state object contains a list of records, where each record corresponds to a snapshot. | |
| Snapshots are kept around forever. | Snapshots are only kept around until they're explicitly disposed.† |
Records are stored in a MutableList. |
Records are stored in a linked list. |
| Snapshots don't support nesting. | Snapshots can be nested arbitrarily. |
It's possible for multiple takeSnapshot calls to return the same snapshot, which means multiple callers could see the same changes. |
Every snapshot is guaranteed fresh – this is actually a very important detail, and we'll see why in a bit. |
† It's possible to modify our code to support disposal too, but I'll leave this as another exercise.
That said, I hope this is enough of a teaser to demonstrate how using an internal list of records can give a mutable state object some superpowers, and to start to understand why the low-level state object APIs in Compose look the way they do. So, let's take a look!
The StateObject interface
Every class that represents a unit of state in Compose implements the StateObject interface. This interface is what truly defines "a type that holds some state that interacts with the snapshot system". It doesn't need to be part of the public API of the state type. Rather, it's the API that the snapshot system uses to manage records within the class. But you can't just slap a : StateObject on your custom data structure and make it magically work with snapshots. You'd still need to override two members:
interface StateObject {
val firstStateRecord: StateRecord
fun prependStateRecord(value: StateRecord)
// There's actually one other optional method, but
// I've omitted it for now to keep things simple.
}
Oh look, state records! firstStateRecord returns the head of the linked list of records, and prependStateRecord adds a record to the list – it's effectively just the setter for the firstStateRecord value. It doesn't even need to link the new record to the previous head, the runtime does that itself. The internal concrete implementation of MutableState that mutableStateOf returns implements this interface. SnapshotStateList and SnapshotStateMap both implement it. And implementing it is fairly straightforward – all three of these classes simply store firstStateRecord in a var and set it from prependStateRecord.
To tie this back into our Weather class, if we wanted to make Weather an official state object, it would need to implement this interface.
Implementing StateObject itself is trivial – the real nitty gritty of the implementation of a StateObject deals with the StateRecord class itself.
The StateRecord class
StateRecord is an abstract class that implementations of StateObject are expected to subclass and use to store their actual data. It's an abstract class instead of an interface because it has internal-only properties that store information about the Snapshot itself, and the pointer to the next record in the list.
Subclasses of StateRecord only have to implement two methods:
abstract class StateRecord {
// Creates a new instance of the same concrete subclass.
// The returned record will be passed to assign.
abstract fun create(): StateRecord
// Copies the value into this state record from another of
// the same subclass.
abstract fun assign(value: StateRecord)
}
Every StateObject starts with a single StateRecord – the initial value of firstStateRecord. When the runtime needs to create a new record, it:
- Calls
createon the current record, then - calls
assignon the new record to copy the contents over from the current record, - sets the internal
nextpointer on the new record to thefirstStateRecordand the internal snapshot ID to point to the current snapshot, then finally - calls
prependStateRecordto officially add it to the list.
There's nothing magic here – this is about the simplest implementation of a generic linked list you can build. It doesn't even have any delete operation! It doesn't need to delete records because they can be reused: to avoid allocating more than absolutely necessary, create isn't always called – when a record becomes unreachable, it's not removed from the list but marked as inactive and will be re-used the next time a new record is needed.
New records are only created (or reused) when necessary – so when is it necessary? Only the first time a state object is written to in a particular snapshot. That is, state objects are copy-on-write data structures.
Let's try to convert our Weather class to be an official Compose StateObject:
class Weather(temp: Int, humidity: Float) : StateObject {
// We keep a more specifically-typed pointer to the
// head of the list to avoid having to cast it
// everywhere.
private var records = Record(temp, humidity)
override val firstStateRecord: StateRecord
get() = records
override fun prependStateRecord(value: StateRecord) {
// This cast is always safe since the runtime
// guarantees it will only pass values in that
// we gave it.
records = value as Record
}
var temp: Int
// I'll explain these readable and writable calls
// below.
get() = records.readable(this).temp
set(value) {
records.writable(this) {
temp = value
}
}
var humidity: Float
get() = records.readable(this).humidity
set(value) {
records.writable(this) {
humidity = value
}
}
private class Record(
var temp: Int = 0,
var humidity: Float = 0f
) : StateRecord() {
override fun create(): StateRecord = Record()
override fun assign(value: StateRecord) {
// This cast is also guaranteed safe by the
// runtime.
value as Record
temp = value.temp
humidity = value.humidity
}
}
}
The main changes we had to make are:
- Replace the
MutableList<Record>with a pointer to the head of the linked list. - Implement the
StateObjectmembers by accessing our list head pointer. - Make
RecordsubclassStateRecordand with fairly trivial implementations of its methods. - Use the
StateRecord.readable()andStateRecord.writeable()extension methods to retrieve the record for the current snapshot for reading and writing operations, respectively.
That last point is the only thing we haven't already covered. In our naive implementation, we got the current record by looking up the currentRecordIndex in the records list. We didn't make a distinction between read and write records. Compose does make this distinction, for a couple reasons:
- Efficiency. Unlike our implementation, Compose doesn't actually create new records when a snapshot is taken – it only does so when it absolutely needs to, which is the first time a
StateObjectis written to in a new snapshot. - Change tracking. This post has mostly ignored observability, but the
readableandwritablemethods are what do the actual reporting of reads and writes to their respective snapshot observers.
At first glance, it might seem like
StateObjectcould be generic on aStateRecordsubtype. However,StateRecordhas methods that refer to itself, and since Kotlin doesn't have self-types, avoiding generics keeps the code a lot simpler. Also, since this is such a low-level API that most developers are intended to never have to even have to know about, it's not a huge burden for the few concrete implementations that exist to have to do a cast.
State reads
The readable function allows multiple snapshots to read from the same record by looking up which record is "closest" to the current snapshot. Conceptually, it looks in the parent snapshot to see if it has a record, and if not keeps searching up the snapshot "tree". In reality, it doesn't walk a tree, it just does some integer comparisons. If that's unsatisfyingly vague, it's only because to explain it fully you need to understand how MVCC tracks snapshots. The only time a read can't happen is when reading a StateObject that was initialized after the current snapshot was created. If you've ever gotten an IllegalStateException with the message "Reading a state that was created after the snapshot was taken or in a snapshot that has not yet been applied", that might be why (although in practice it usually means a bug in Compose itself, not your code). You can see this happen for yourself by going back to the sample code in the amuse-bouche section and moving the val message = mutableStateOf("") to after the line that creates helloSnapshot.
State writes
Writes, however, are a little more interesting. The snapshot runtime guarantees that every snapshot will get its own record to write to, a record that no other snapshot can see. (This is different from our naive Weather snapshot implementation, where multiple callers of takeSnapshot could potentially mutate the same record.) The writable function starts by doing the same thing as readable: looking for the "closest" record to the current snapshot. When it finds one, if that record is associated exactly with the current snapshot (and not shared with a parent), then it knows that no other snapshot can see it, and so it gets returned and the StateObject is free to write directly to it.
The details of how snapshot nesting works are interesting, and I'll hopefully cover them in a future post about MVCC, but they're not super important to know for implementing a state object so I'll leave that discussion out for now.
This means that most state writes to the same StateObject in the same snapshot are pretty cheap, since they can mutate an existing object in-place. The exception is the first time each StateObject is written in a particular snapshot. In that case, the initial record lookup will probably return a record from a parent snapshot, so it can't be written to directly since those writes would be visible to that other snapshot. This is when the runtime has to either create a new record or find an unused one, assign it from the current record, and ensure it's in the StateObject's record list before passing it to the writable block to actually perform the write.
The readable and writable functions also incur a little overhead themselves:
- They both report the read or write to the snapshot observers, if present.
- They both have to walk the linked list of records, although this is typically fast because the list is usually quite small.
writablehas to acquire a lock which prevents new snapshots from being taken until the write is complete. This is also why thewritablefunction takes a function instead of just directly returning a value – the function is called while that lock is held.
To summarize:
- Reads are cheap.
- Initial writes are only as expensive as it is to create a copy of the record (via the
assignmethod). - Subsequent writes in the same snapshot are only as expensive as it is to mutate the current record in-place.
In the case of MutableState, copying is cheap – the record just holds a reference to the current value, so it's just a pointer copy. Our latest Weather implementation is fast for the same reason, it's just two pointers. The SnapshotState(List|Map) classes are also really fast at copying – they store immutable, persistent collections, so they make new records point to the same instances of those collections, and instead make copies on each actual write – but those copies are fast because the collections are persistent and optimized specifically for this sort of thing. In general, if you're working with a data structure that can efficiently copy-on-write, it's almost trivial to convert it into a StateObject.
Example walkthrough
Now that we've seen how to build a custom StateObject, let's walk through some snapshot code and look at how snapshot operations correspond to record operations.
This example will use low-level snapshot APIs to be able to enter different snapshots that are open concurrently without dealing with threads. Note that in most code, you should never need to use these APIs – Snapshot.withMutableSnapshot and snapshotFlow are much more convenient for most use cases – but the APIs in this code are public, so you can run this code yourself.
The complete, runnable code for this section is available in this gist.
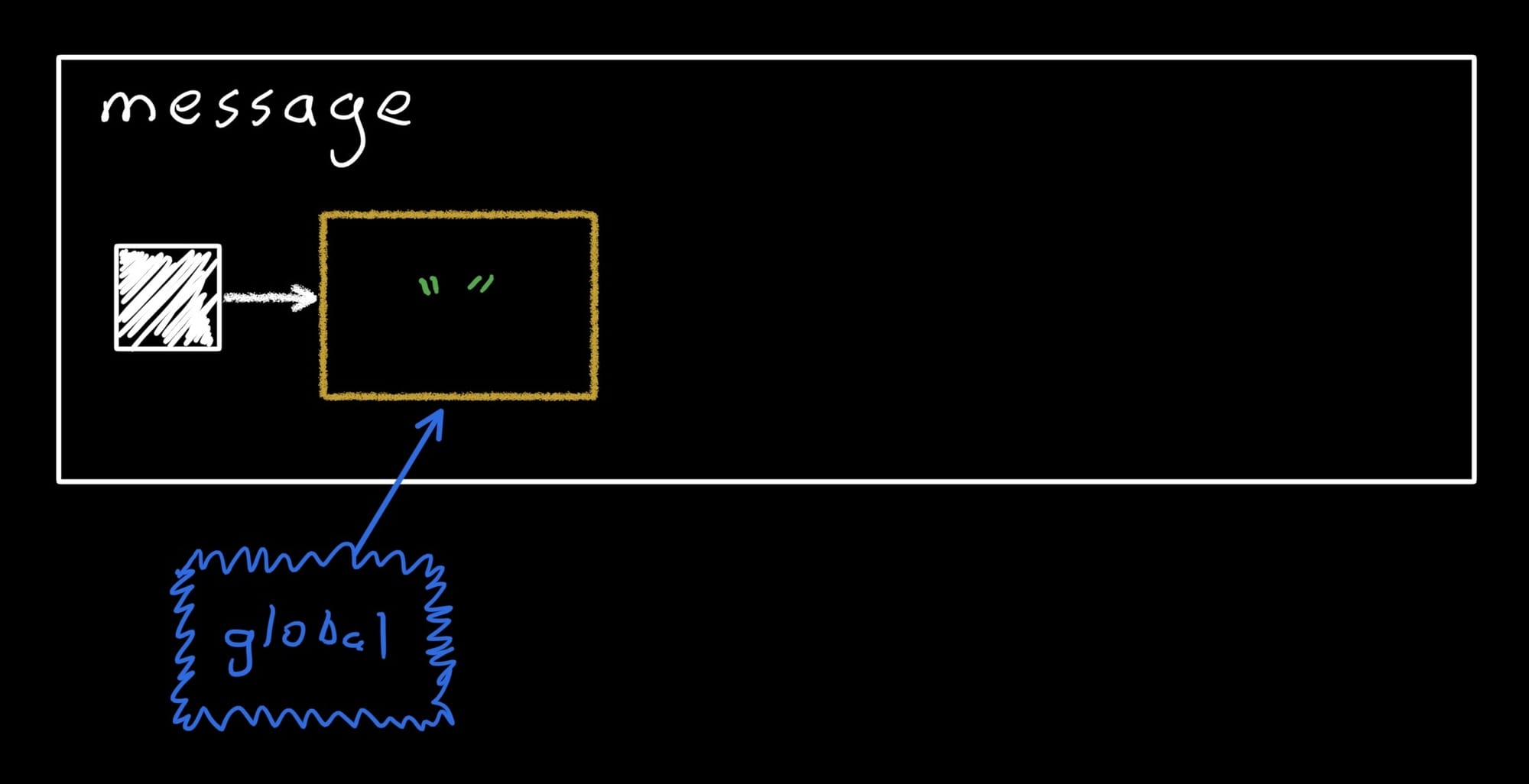
First we'll instantiate a state object so we have something to manipulate in the snapshots. Let's just use a MutableState to keep things simple:
val message = mutableStateOf("")
In the sketch below, the white box represents the message state object. The solid white square is the firstStateRecord pointer, and the yellow boxes are the individual records. The currently-open snapshots are shown in squiggly blue lines below, with an arrow pointing to the record that they will write into. At this point, message contains a single record holding an empty string, and the only snapshot is the global one (remember, all code that isn't in an explicit snapshot is actually in the global snapshot).
Now let's create a snapshot.
val snapA = Snapshot.takeMutableSnapshot()
The takeMutableSnapshot function is what withMutableSnapshot uses to create its snapshot. Now that we have a snapshot, let’s make some changes inside it.
snapA.enter {
message.value += "Hello"
// Changes performed inside a snapshot are
// immediately visible within that snapshot.
assertEquals("Hello", message.value)
}
// Any changes performed in a snapshot are not visible
// to its parent snapshot or any other snapshots until the
// snapshot is applied.
assertEquals("", message.value)
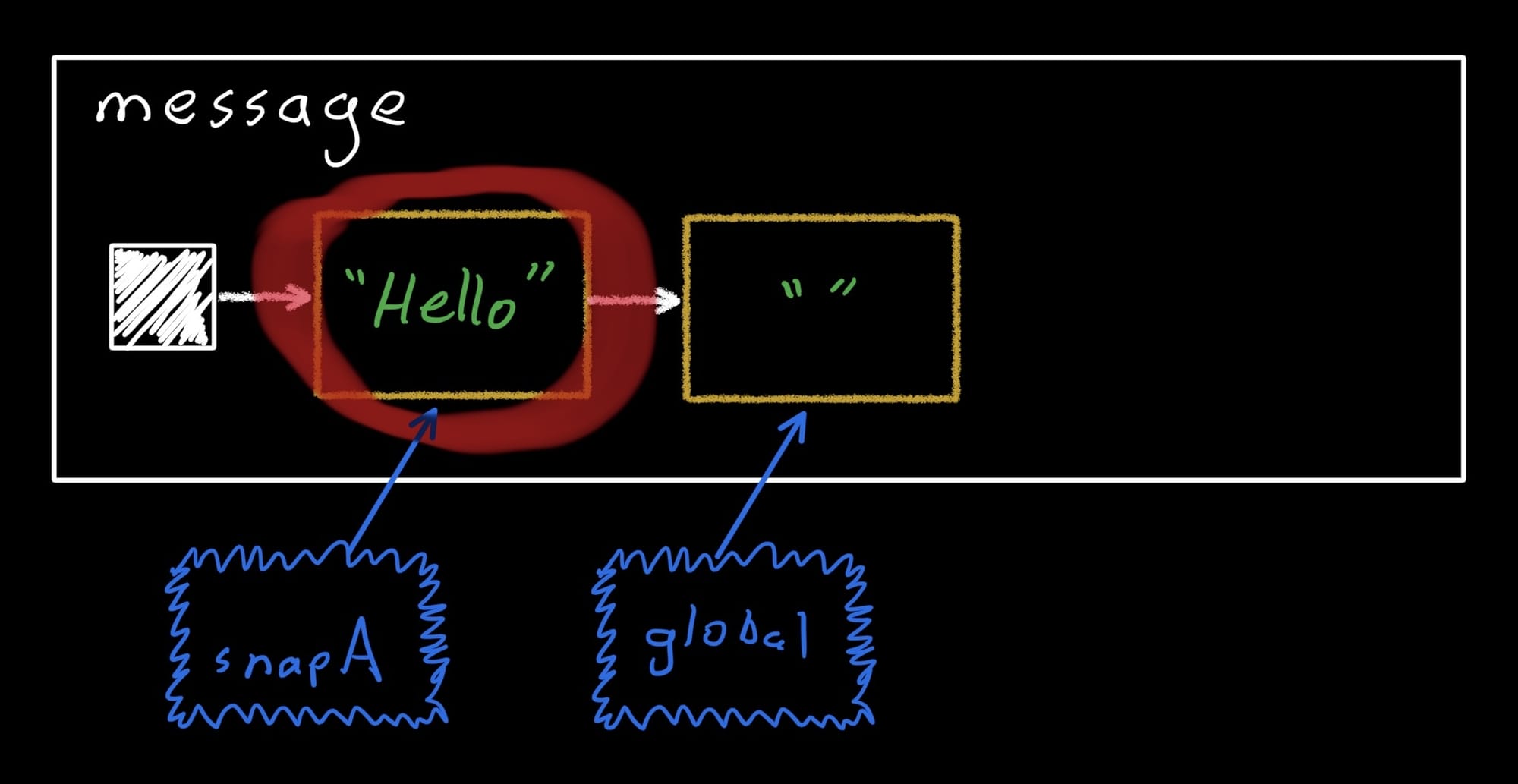
The enter method marks the snapshot as the current one for the code inside the lambda passed to it, and runs that lambda. (The way it does this is not relevant to this post, but if you’re curious stay tuned for my MVCC post.) As soon as the enter block returns, we’re back in the global snapshot, and the changes we just made are no longer visible. Note that snapA is still open since we haven’t applied it yet – we’ll do that later. So now message looks like this:
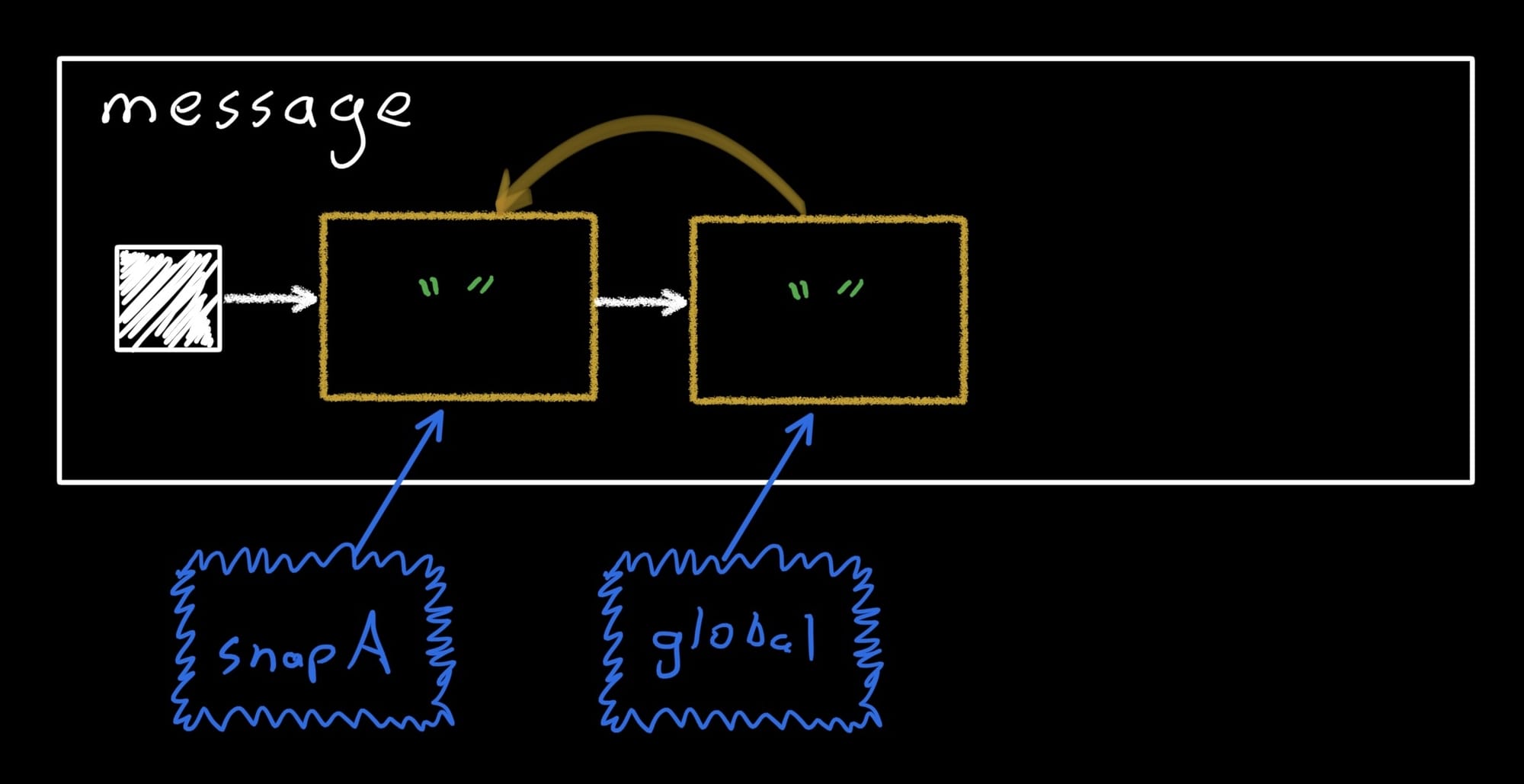
The snapshot system created a copy of the first record and linked it into the list. The global snapshot still only sees the initial record, while snapA sees the new record. Then when we wrote the new string, it stored it in the new record:
Before we apply snapA, let’s open another snapshot from the global one:
val snapB = Snapshot.takeMutableSnapshot()
snapB.enter {
message.value += "world"
assertEquals("world", message.value)
}
assertEquals("", message.value)
snapB is entirely isolated from snapA and from the global snapshot. Since we still haven’t disposed any snapshots, the system had to create yet another record – also copied from the initial one:
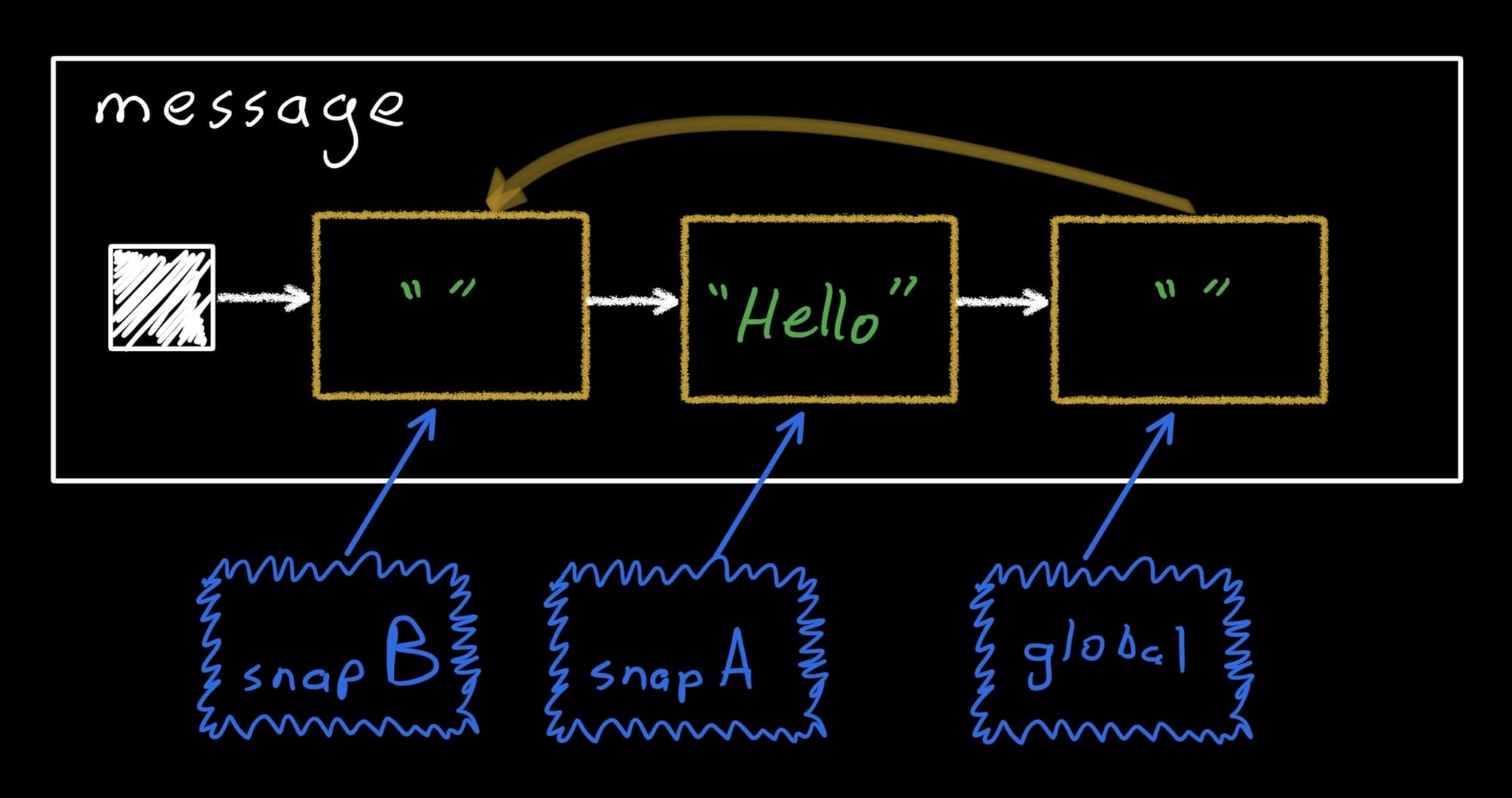
And then the new string was written into the new record:
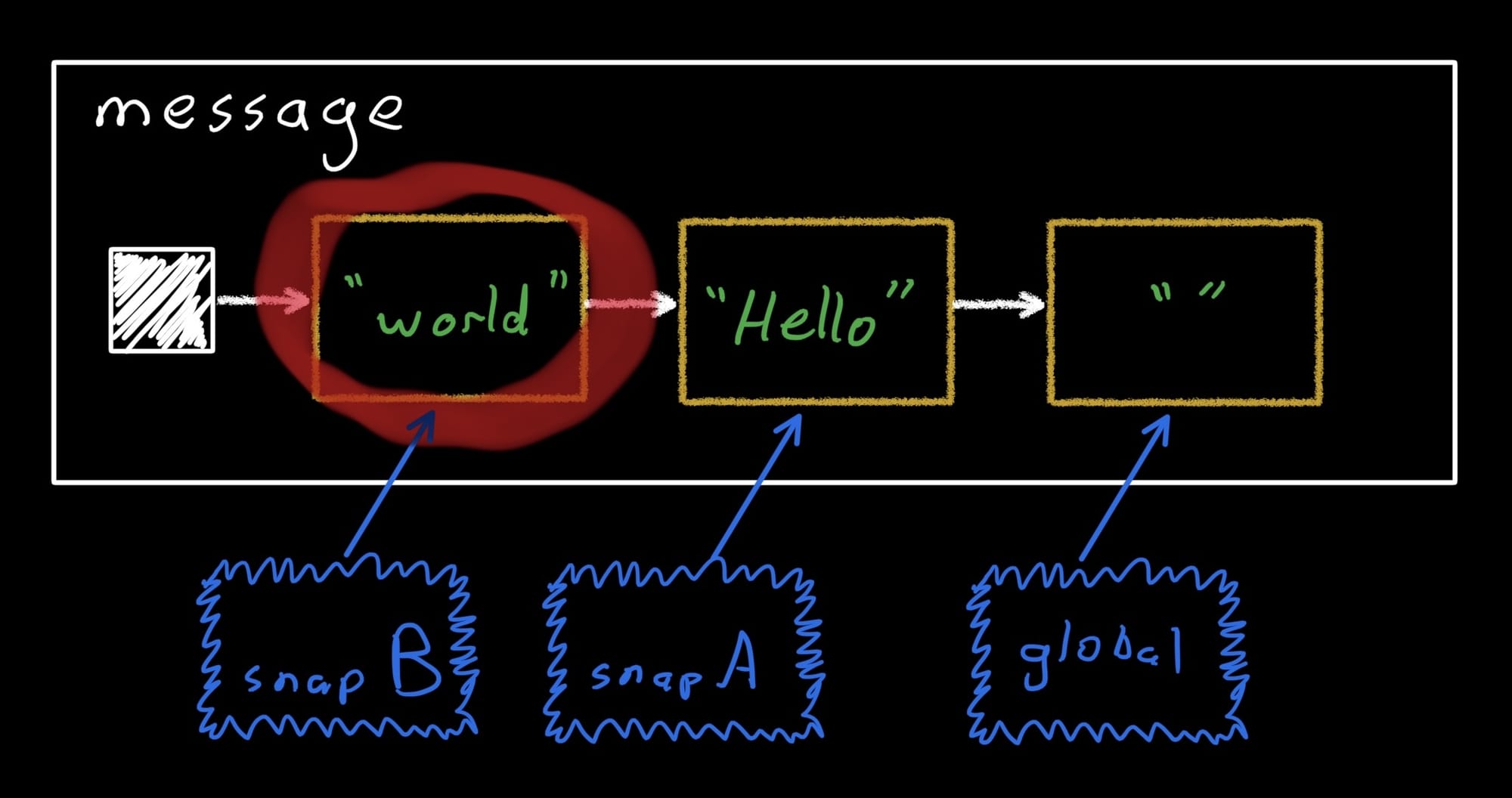
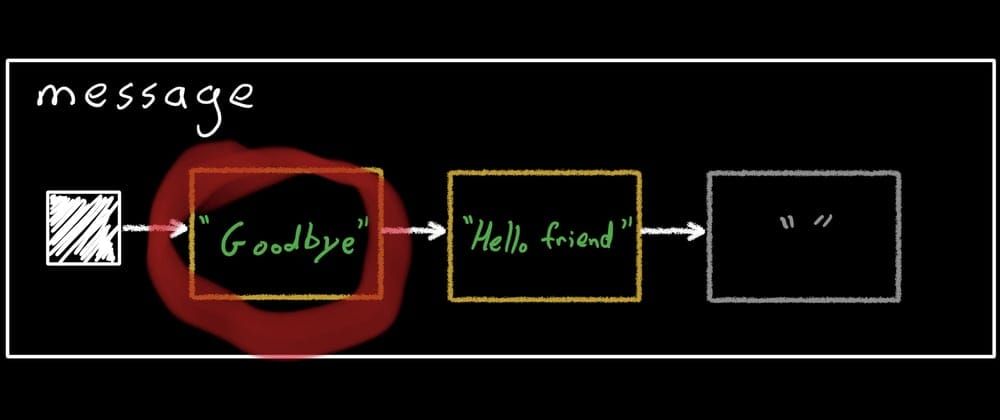
Now let’s go back to snapA and make another change.
snapA.enter {
message.value += " friend"
assertEquals("Hello friend", message.value)
}
snapA still writes into the second record:
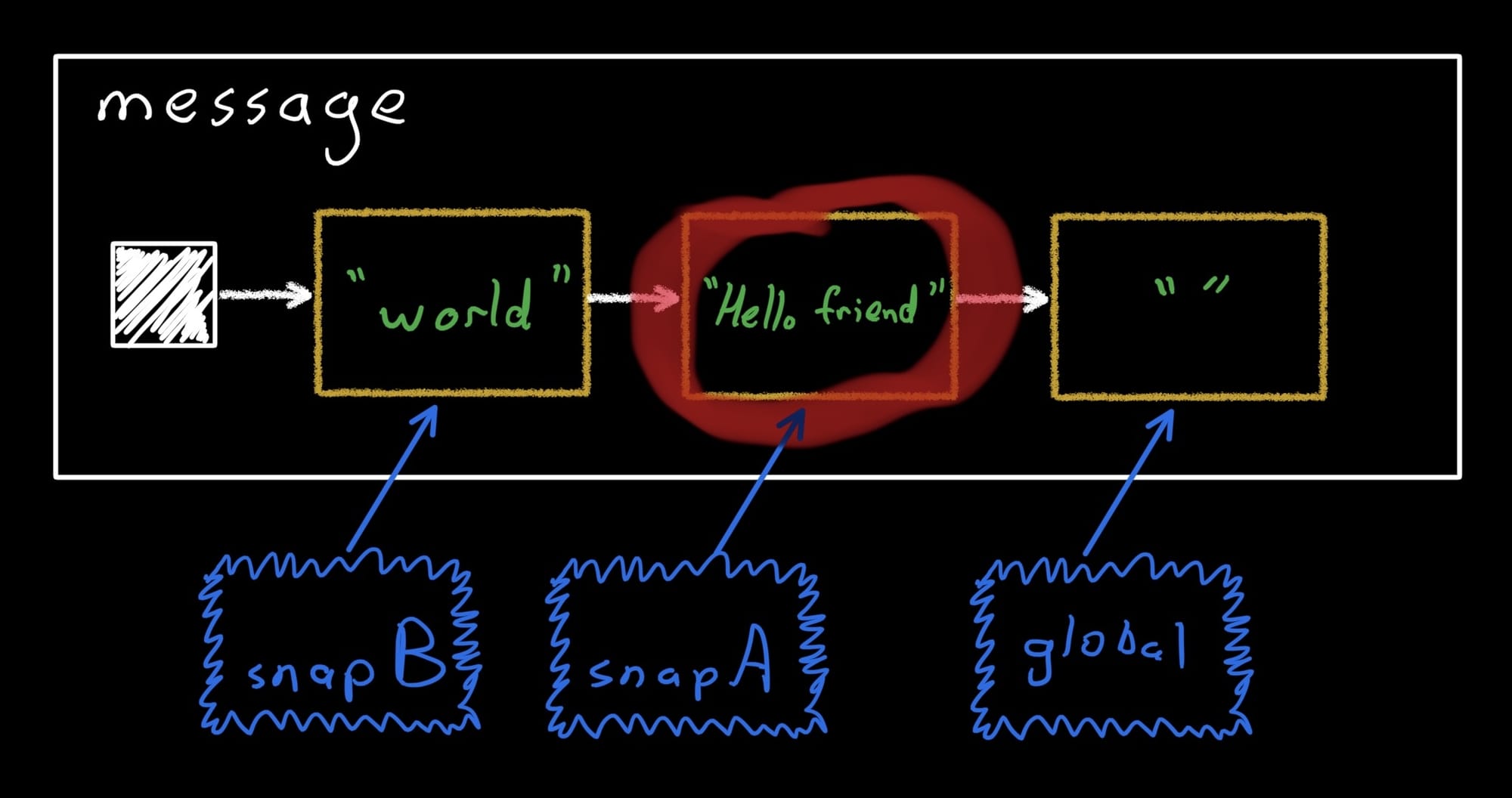
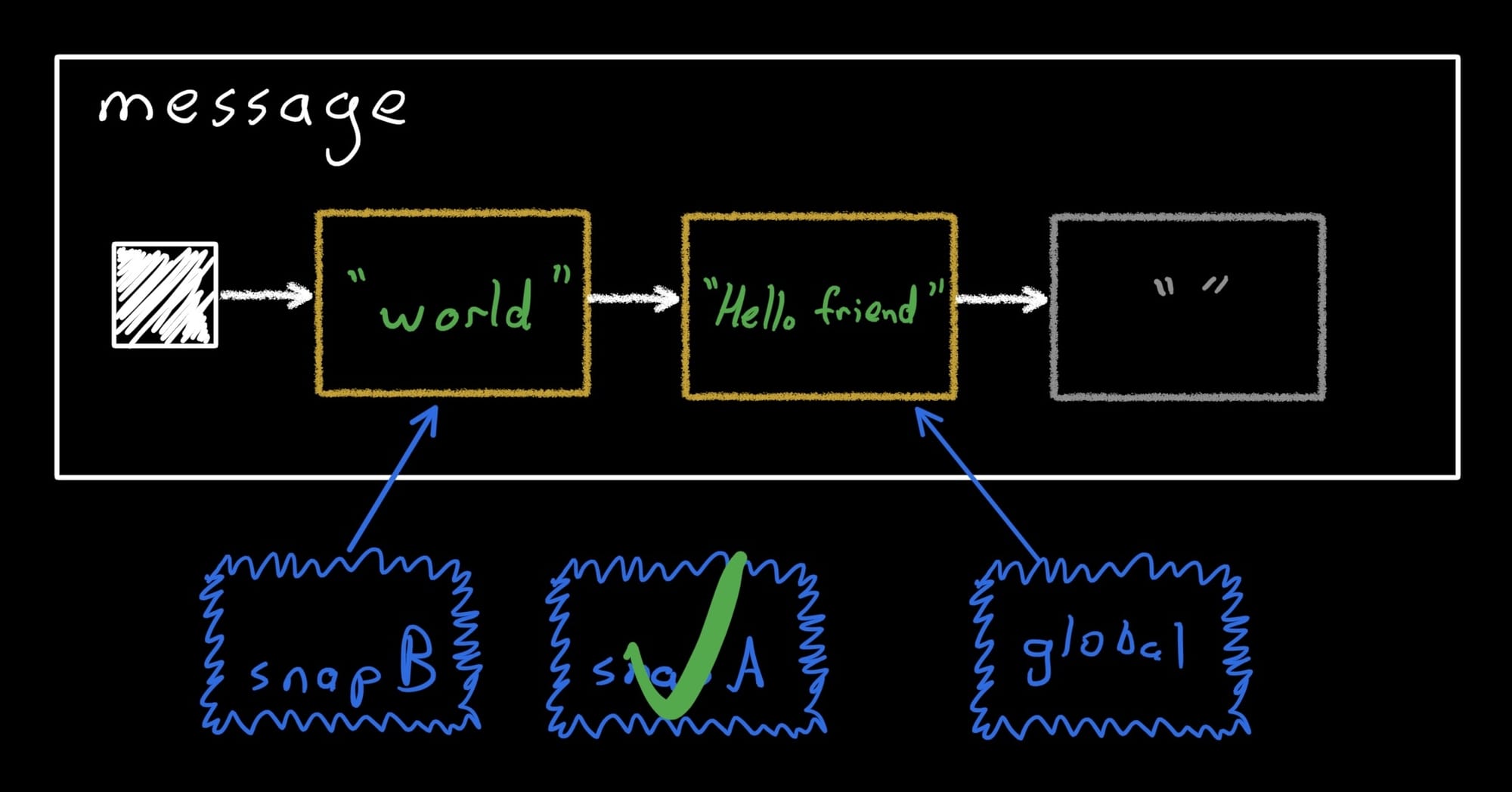
Ok let’s apply snapA (and dispose it, so we don’t leak memory):
snapA.apply()
snapA.dispose()
assertEquals("Hello friend", message.value)
Finally, the global snapshot now points at the record we created for snapA. Note that the initial record is still around, and still in the list, but it's no longer visible to any snapshot.
Since we just applied snapA, snapB will conflict. We could try applying it, but I'm going to just dispose it immediately.
snapB.dispose()
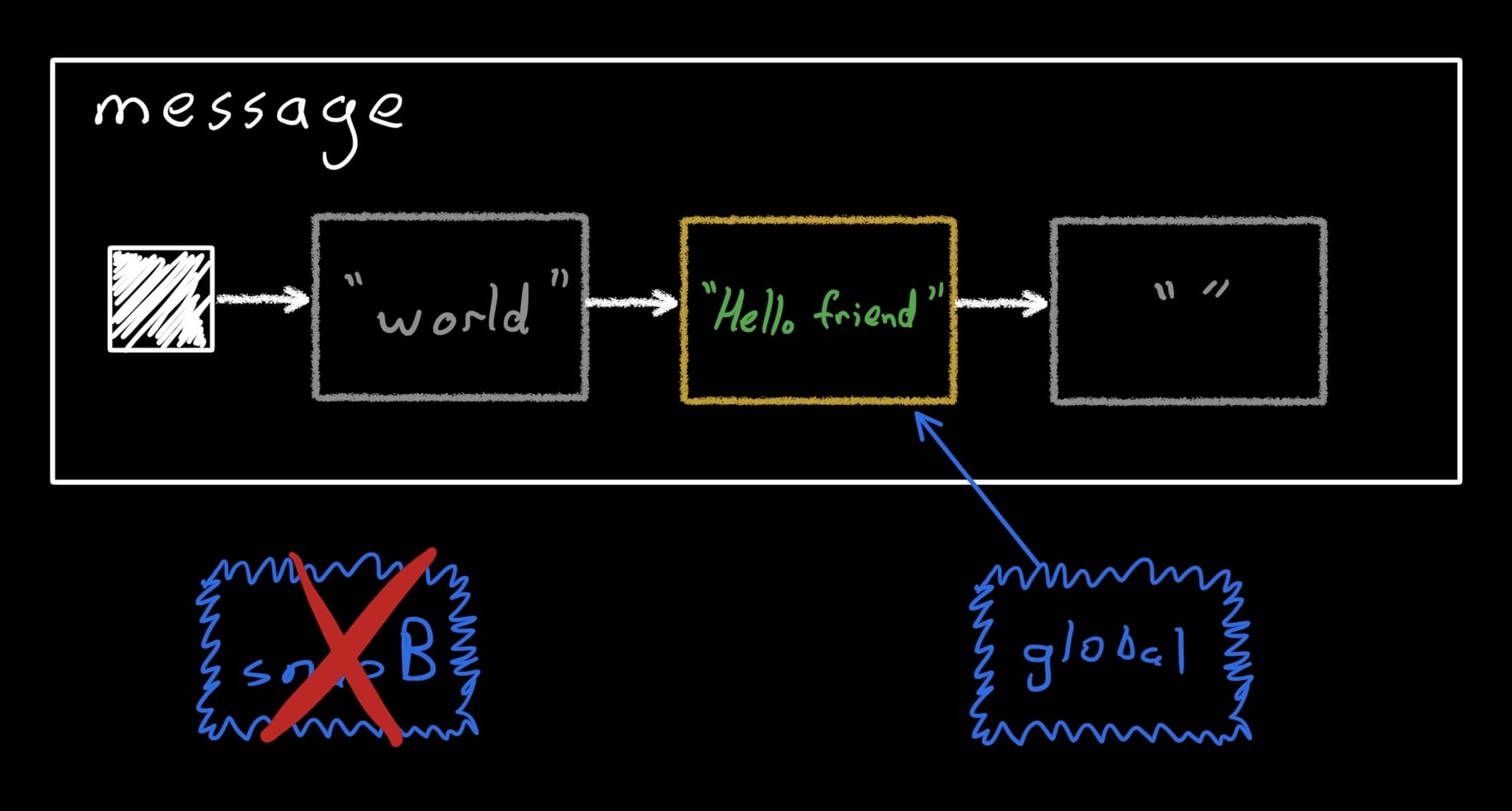
The message object still has all three records, but now only one of them is accessible, and the only open snapshot is the global one. For one last demonstration, let's open a third snapshot and see what happens.
val snapC = Snapshot.takeMutableSnapshot()
snapC.enter {
message.value = "Goodbye"
}
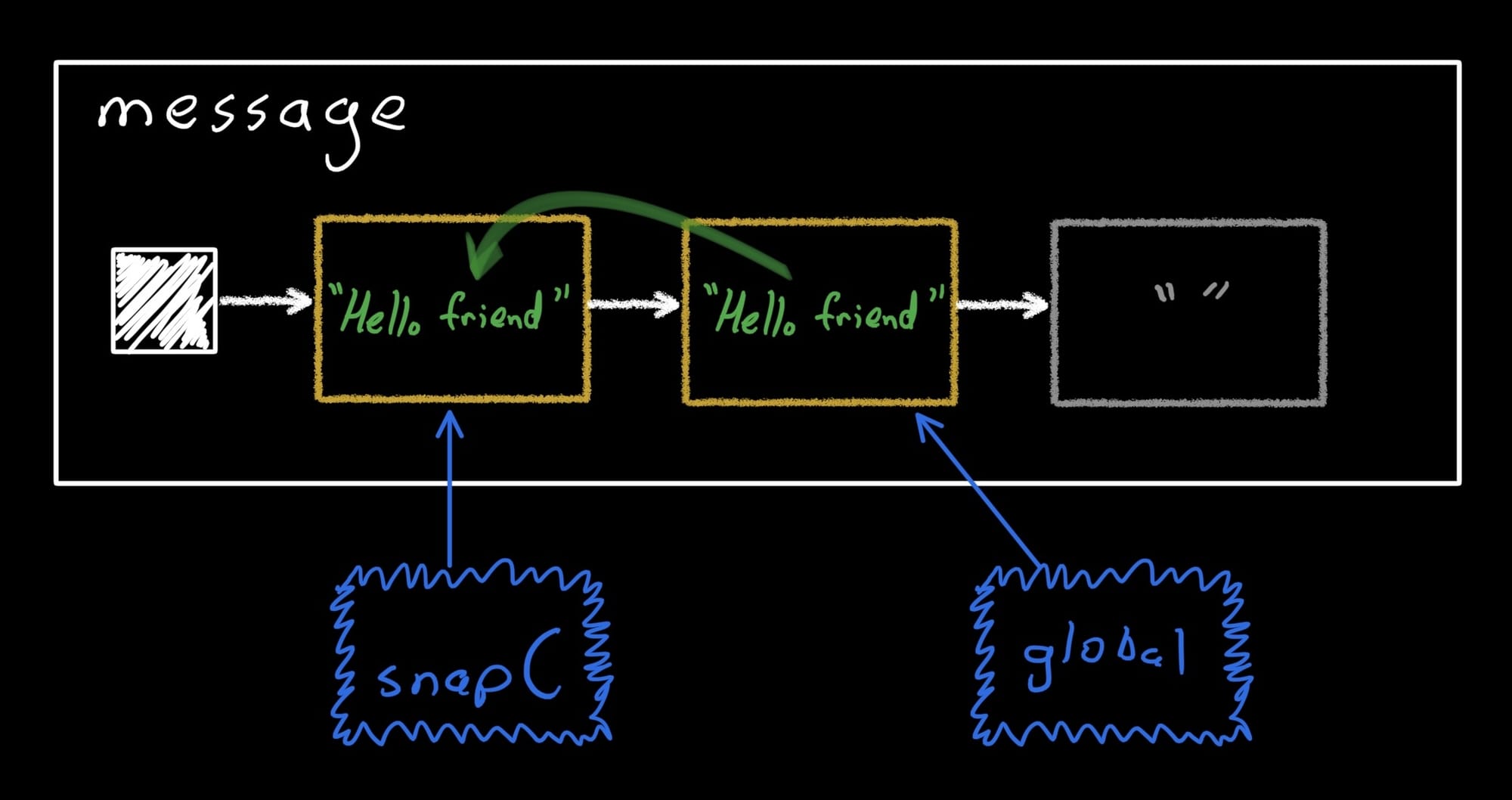
This time, instead of creating a new record, it simply finds the first unused one and reuses it, copying the current global record's data in. Then, it updates the record:
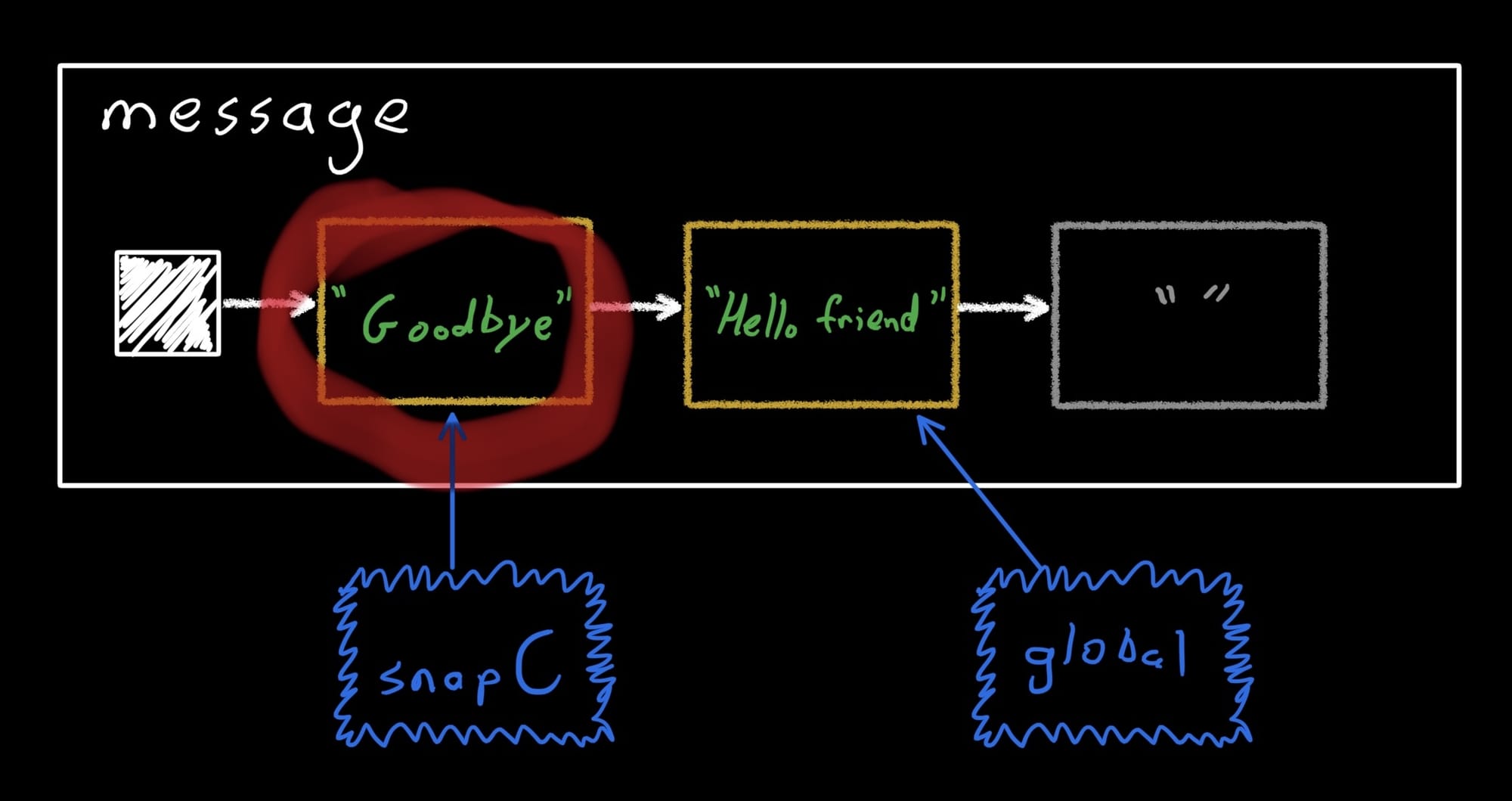
Now we can apply and dispose it, and we're done!
snapC.apply()
snapC.dispose()
assertEquals("Goodbye", message.value)
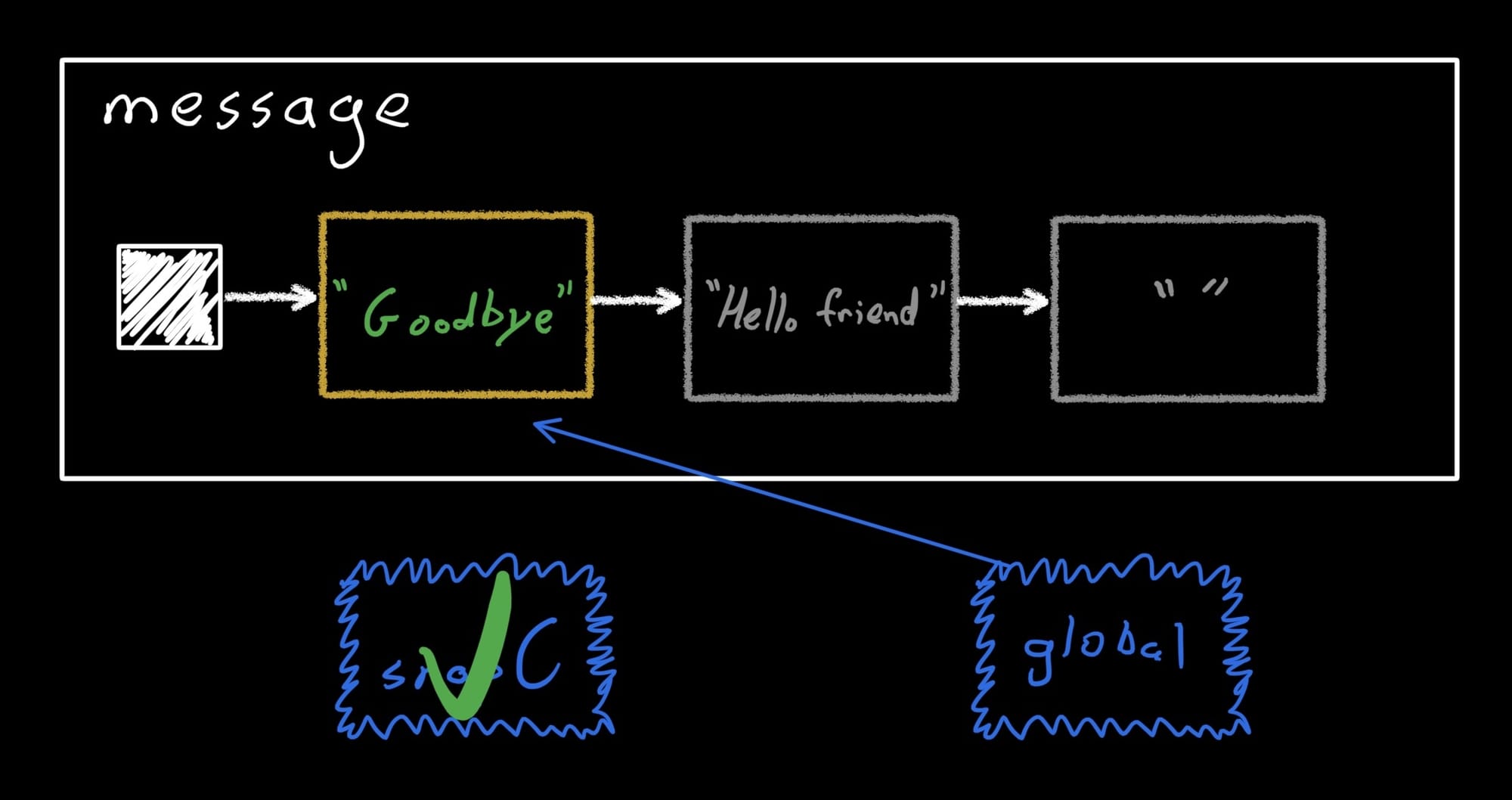
From this example, we can see how StateObjects have the first three properties in ACID:
- Atomicity: The multiple changes to
messageinsidesnapAare made visible to the code outside the snapshots (i.e. the global snapshot) all at once (atomically) by thatapply()call, or not at all, if the snapshot is disposed without applying. - Consistency: Code within each snapshot will see the state values that were current at the time the snapshot was taken, for all state objects. Also, when snapshots that make conflicting changes are both applied, writes are rejected. If we tried to apply
snapBafter applyingsnapA, it would fail, since they both changed the same value. - Isolation: None of the snapshots see changes from any other snapshots while they're open, since they're all using different records.
Conclusion
We're almost done! I hope this post made some inkling of sense – we covered a lot, so let's review:
- Compose's snapshot state system is an in-memory implementation of multi-version concurrency control that provides the first three letters of ACID: atomicity, consistency, and isolation.
- In order to get those benefits, application state must be stored in special "state objects that implement the
StateObjectinterface. StateObjects store their data insideStateRecordobjects.- Each
StateRecordinstance may be readable at any given time by any number of snapshots, but can only be writable by a single snapshot at a time. - Snapshots provide isolation from other snapshots, but not between multiple threads accessing the same snapshot. As a best practice, make sure groups of related operations on snapshot state running on a background thread are performed in a snapshot that only that thread can see, e.g. by using
Snapshot.withMutableSnapshot.
One very important question that remains is, since MutableState, SnapshotStateList, etc. already exist, when is it actually necessary or even appropriate to implement your own custom StateObjects? A lot less than you might think. Like most things in Compose, state objects compose very well. Most app code can get by very well by only using those existing primitives, and building more complex objects that contain them. The Weather class I used as an example is completely contrived – no real app should implement this sort of thing as a StateObject, it would be much better to just store both properties as MutableStates and call it a day.
The exception is when a class has multiple properties and there are dependencies between those properties. For example, if you have class Range(var min: Int, var max: Int) the implicit assumption is that min <= max. If these are implemented by mutableStateOf() then you could apply two snapshots that do not collide with each other and do not violate this constraint, but taken together, do violate the constraint – this would be "inconsistent" in ACID terms. For example, given the initial value [0, 100], one change could be [75, 100] and the other could be [0, 25]. Both are valid as they don't violate the constraint and they don't collide because one changes min and the other changes max, but taken together they become [75, 25] which does violate the constraint. If you implement Range as a StateObject then the values are taken together or not at all. That is, either [75, 100] is taken or [0, 25], not both.
There might also be a performance benefit. In the Range case there were only two fields, but some data structures have a more complex internal structure, where a single operation on the data structure requires reading and writing large parts of the internal data together to execute the operation. For example, consider a data structure that's implemented as a tree and may need to perform a rebalancing operation as part of a write. It might need to be a StateObject for the consistency reason above, but it also might perform better. If each node in the tree contains its own MutableStates for node pointers and content, then every read from the tree will require performing a large number of snapshot state reads, and in the case of rebalancing, a large number of writes as well. Since readable and writable incur their own overhead, this might be a problem. Furthermore, each of those individual reads might need to be tracked by the snapshot's read observer, which takes more memory and computation. Replacing all those individual reads and writes with a single one for the entire operation reduces stress on all these parts of the system and allows the tree to do whatever internal manipulations it requires much more efficiently, and makes it easier to keep the data structure consistent.
Thanks for staying with me until the end! If you enjoyed this and want more, I've given a talk about how the actual algorithm snapshots use works: Opening the Shutter on Snapshots.
Also, check out my other articles about Compose state.
Thanks to Chuck Jazdzewski and Alejandra Stamato for their thorough reviews!