Plumbing data with derived state in Compose

Jetpack Compose has powerful features for managing mutable state and observing state changes implicitly. The snapshot state system allows framework code to specify how to observe state changes. It makes it easy to declare state that will automatically be observed, no matter how it’s accessed.
This post occasionally uses Compose UI to demonstrate how some of these concepts could be applied in a realistic context, but the core underlying concepts have nothing to do with Compose UI and could be used with any other composable code, or even code that is using snapshot observers without composables.
The following code is a common shape in Compose code:
class ScreenState {
var text by mutableStateOf("")
var checked by mutableStateOf(false)
}
@Composable fun Screen(state: ScreenState = remember { ScreenState() }) {
Row {
Checkbox(state.checked, onCheckedChange = { state.checked = it })
TextField(state.text, onValueChange = { state.text = it })
}
}
The "state" of the Screen composable is "hoisted" into the ScreenState class, which can be easily unit tested. The Screen then declares UI based on the state read from the class, and sends state updates to the class. The state class uses MutableState objects internally to allow Compose to track changes, but that's nicely hidden underneath a clean API surface that just exposes regular mutable Kotlin properties.
The snapshot state system works great for this sort of thing. But it's a really powerful tool, and this sort of simple example barely scratches the surface of what it can do. While it's included in the Compose runtime artifacts, the snapshot system is completely decoupled from Compose UI and even the rest of the Compose runtime. We can use it to build things that have nothing to do with Compose – any program state that can change over time, and to which you need to react, the snapshot state system can help out.
In this blog post, we'll demonstrate some of this flexibility by building a spreadsheet-like library for performing simple arithmetic calculations. We'll use Compose's snapshot state system to make all the calculations reactive, and maybe learn a new trick or two along the way.
Requirements
We're going to building something called a "worksheet". A worksheet has zero or more rows that look something like this:
subtotal=31.50
taxRate=0.15
partySize=3
taxAmount=subtotal*taxRate
total=subtotal+taxAmount
total/partySize
This particular worksheet could be used to help split the bill at a restaurant. Each row of a worksheet:
- is a mathematical expression
- can be evaluated and produce a result value
- can optionally define a name for its value
- can refer to names defined in previous rows
API Design
Let's start by defining the API we want to expose, and work backwards from there. A worksheet is just a series of rows. Let's define an interface for a row:
interface Row {
/** The expression to calculate. */
var input: String
/** If [input] could not be evaluated, this list explains why. */
val errors: List<String>
/** The result of evaluating [input]. */
val result: Value?
}
Note that this API exposes both read-only and read/write properties. Keep in mind that, in Kotlin, just because a property is read-only doesn't mean it's immutable – it just means there's no way for external code to change it. Typically it would be a bad practice to change the underlying data exposed from a val being used by a View, for example, but Compose lets us do that safely – when the property is read from a snapshot observer, that observer will get notified automatically when the underlying data changes. If this seems like magic, hopefully my blog post about the snapshot system takes some of the mystery away.
Performing calculations
In order to actually parse expressions and produce actual numbers, we're going to cheat a bit and assume the existence of a simple library to do that for us, since parsing and interpreting a grammar are far outside the scope of this post. Our imaginary API can parse string expressions and evaluate them. The entry point is a simple function that returns an executable Expression and/or some errors:
fun parse(input: String): ParseResult
data class ParseResult(
val expression: Expression?,
val errors: List<String> = emptyList()
)
An Expression has a single operation: evaluation. The result of evaluating an expression is similar to that of parsing: a result value, the name given to the result if specified, and/or a list of errors.
interface Expression {
fun evaluate(context: EvaluationContext): EvaluationResult
}
data class EvaluationResult(
val value: Value,
val assignedName: String? = null,
val errors: List<String> = emptyList()
)
In order to evaluate an expression, we need to pass it an EvaluationContext, which is simply a way to look up values for names. If the expression references a name, the context will be asked for the value for that name. If the name was defined by a previous row, its value is used, otherwise the name is considered "undefined" and evaluate returns an error. Names can be "overwritten" – if multiple rows define the same name, then when the name is referenced, the value from the nearest previous row is used.
interface EvaluationContext {
/**
* Returns the value associated with [name],
* or null if the name is not defined.
*/
fun getValueForName(name: String): Value?
object EmptyEvaluationContext : EvaluationContext { … }
}
Lastly, the Value class is an abstraction of the result of a calculation.
The GitHub project for this post includes a simple, naïve-but-mostly-working implementation of this API, so if you'd like to play around with the rest of the code in this post it's probably easiest to clone that repo.
Implementing worksheets
So far we've got an API we need to implement and a helper calculation library to do the hard stuff. All we have to do is wire them up, and we're done! Well, except that wiring them up is the whole point of this blog post, so we'll take it nice and slow. (Now's a great time to top off your coffee.)
Let's start with the smallest piece we can: Row. Remember it looks like this:
interface Row {
var input: String
val errors: List<Error>
val result: Value?
}
Ok, let's give it a try.
class RowImpl {
override var input: String = ""
override val errors: List<Error> = emptyList()
override val result: Value? = null
}
This doesn't actually do anything though, so let's do some calculations:
class RowImpl : Row {
override var errors: List<Error> = emptyList()
private set
override var result: Value? = null
private set
override var input: String = ""
set(value) {
// Don't do any work if the input didn't actually change.
if (value == field) return
field = value
// Parse the input and report any errors.
val (expression, parseErrors) = parse(value)
this.errors = parseErrors
// If parsing failed, we can't evaluate, so just give up.
if (expression == null) {
this.result = null
return
}
// The input was valid, so try to run it and report the result.
val (resultValue, assignedName, evalErrors) =
expression.evaluate(EmptyEvaluationContext)
this.result = resultValue
this.errors += evalErrors
}
}
That's a decent chunk of code, and it will work for a single row, but there are a few issues:
- We're updating the row properties
errorandresult, but those are just normal properties so there's no way to find out when they change. Whatever setsinputmust also make sure to re-read the other properties. - We're always using the
EmptyEvaluationContext, which means that names defined in previous rows will not be visible to subsequent ones.
Let's solve them one at a time.
Making rows reactive
If you've been wondering when, in this blog post apparently about how cool snapshot state is, we're actually going to see a snapshot state, your patience is about to be rewarded! Let's use MutableStates to make this class automatically publish updates:
class RowImpl : Row {
override var errors: List<Error> by mutableStateOf(emptyList())
private set
override var result: Value? by mutableStateOf(null)
private set
private var _input by mutableStateOf("")
override var input: String
get() = _input
set(value) {
// Don't do any work if the input didn't actually change.
if (value == _input) return
_input = value
// The rest is the same as before.
…
}
Wow, that was… almost too easy? All we did was add some by mutableStateOf()s and all three properties became observable! This looks just like a typical hoisted state class. We could use it to back a simple UI, for example something like this:
@Composable fun RowEditor(row: Row = remember { RowImpl() }) {
Column {
TextField(
value = row.input,
onValueChange = { row.input = it }
)
// Format decimal numbers with 3 decimal places.
Text(row.result.toString())
row.errors.forEach { error ->
Text("Error: $error", color = Color.Red)
}
}
}
We get some nice optimizations from doing this too. If we get a new input, but it evaluates to the same result value, result won't report a change because mutableStateOf will, by default, ignore writes that are equal to the current value. In the Compose UI code above, that doesn't actually save us anything since the entire Column lambda has to recompose anyway any time any of the properties changes. For an explanation of why this is the case, see my post about recomposition. However, if this code gets more complex in the future, and maybe factored into more functions, it's nice to know that it will automatically do the right thing.
Let's move on to the second issue.
Referencing previous rows
So far we've only supported single, independent rows, but one of the features of this "worksheets" thing is that you can define names for calculations and refer to them later. With our calculation API, we can support this by providing EvaluationContexts that vend the results of previous rows. A simple way to do this is to make RowImpls into a linked list. Each row points to the previous row and stores the name, if given, of its calculation. The evaluation context of any row is then defined recursively as the context of the previous row plus that row's evaluation context. If that seems like a mind bender, it might make more sense in code:
class RowImpl : Row {
// Don't forget to use mutableStateOf!
var previousRow: RowImpl? by mutableStateOf(null)
private var name: String? by mutableStateOf(null)
…
override var input: String
set(value) {
…
// The input was valid, so try to run it and report the result.
val evalContext = previousRow?.evaluationContext
?: EmptyEvaluationContext
val (resultValue, assignedName, evalErrors) =
expression.evaluate(evalContext)
this.result = resultValue
this.errors += evalErrors
// Store our name so we can look it up from the evaluation context.
this.name = assignedName
}
val evaluationContext = object : EvaluationContext {
override fun getValueForName(name: String): Value? {
// If our name matches, we're done!
return if (name == this.name) result else {
// Continue searching up the worksheet.
previousRow?.evaluationContext
?.getValueForName(name)
}
}
}
}
This isn't very efficient since we're potentially searching up the entire list of rows on every evaluation, and every evaluation of all rows below us – if every row references all the rows before it, this is an O(n!) algorithm (I think – in any case, it's not great). We'll see a way to improve this a little later on, but for now let's call it good enough, because we have a bigger problem to solve. Consider this simple worksheet:
val row1 = RowImpl().apply {
input = "answer=42"
}
val row2 = RowImpl().apply {
previousRow = row1
input = "answer"
}
When we assign input = "answer" for row2, the property setter will evaluate the expression and set the result to 42. If we later set row2.input = "answer/2", the setter will update the result property to 21, and because that property is backed by a MutableState, any observers will be notified. However, if we set row1.input = "answer=1", observers of row2 will not see the change. This is because when row2.result is read, only the MutableState backing the result property is considered read. The runtime has no way to know that result is actually calculated from, and depends on the result of, row1. We need some way to express that dependency to the runtime. RxJava aficionados may recognize the need for something like a map operator here, but Compose can do even better.
From push to pull
In order to get calculation updates to propagate down the list of rows correctly, we need to ensure that any time a calculation result or errors are read, the runtime observes not only those MutableStates themselves, but also all the states that they are derived from. The snapshot system will observe reads no matter how deep down they are in the call stack, so one way to do this is to change the calculation logic from being "push"-based – where the calculation is performed eagerly when the input is changed – to being "pull"-based – where the calculation is performed lazily when the result is read. This means only a row's actual "inputs" (the input string value and its previousRow) should be stored in MutableStates – everything else should be computed when needed.
I use the terms “push/pull” here because I like how they describe the data flowing through the system, rather than just when it’s computed.
Another way to think of this, if you're coming from a reactive streams background, is that MutableState is a lot like RxJava's BehaviorSubject or Flow's MutableStateFlow. You "push" values into these classes by calling onNext or setting their value property (or when using MutableState's property delegation, by setting the delegated property's value). With streams, these "push" types are generally intended to be used only at the boundary between non-stream-based and stream-based code. When performing calculations on other streams, you want to use operators like map or flatMap to ensure that your stream correctly processes upstream changes. However, because Compose's snapshot system tracks state value reads implicitly, we don't need an operator to achieve the same effect – we just need to make sure we read dependent state values directly every time we need them.
class RowImpl : Row {
var previousRow: RowImpl? by mutableStateOf(null)
// Since this function isn't doing any real work anymore, we
// can always set the value without checking for equality.
override var input: String by mutableStateOf("")
private val _result: Pair<EvaluationResult?, List<String>>>
get() {
// Parse the input and report any errors.
val (expression, parseErrors) = parse(input)
// If parsing failed, we can't evaluate, so just give up.
if (expression == null) {
return Pair(null, parseErrors)
}
// The input was valid, so try to run it and report the result.
val evalContext = previousRow?.evaluationContext
?: EmptyEvaluationContext
val evalResult = expression.evaluate(evalContext)
return Pair(evalResult, parseErrors)
}
override val errors: List<String>
get() {
val (evalResult, parseErrors) = _result
return parseErrors + evalResult?.errors.orEmpty()
}
override val result: Value?
get() = _result.first?.value
val evaluationContext = object : EvaluationContext {
override fun getValueForName(name: String): Value? {
val thisName = _result.first?.assignedName
// If our name matches, we're done!
return if (name == thisName) result else {
// Continue searching up the worksheet.
previousRow?.evaluationContext
?.getValueForName(name)
}
}
}
}
Now every time input is set, we just update a MutableState. When result or errors is read, internally we read _result, which is a computed property with no backing field. The parse and evaluation are run every time _result is read, which means that the input and previousRow properties are read, and because those are MutableStates, if the result or error read is being done in a snapshot observer, that observer will observe input and previousRow as well.
Note that this works even though previousRow is only read indirectly! _result's getter passes our EvaluationContext to evaluate, which may call getValueForName, which in turn is what actually reads previousRow. And so on, recursively, up the row list. In other words, if evaluating the row requires looking up a name in the EvaluationContext, the context is automatically observed. If our expression references any previous row, that row will be observed and trigger us to recalculate. Furthermore, because the context only searches up the row list until the name is found, only the sub list between this row and the nearest previous row that defines the name will be observed. If a name is defined multiple times, the earlier rows defining it won’t be observed since we don’t care - the value is only defined by the most recent row defining the name. Also, if any row between the one defining a name and the one referencing it is changed to suddenly define the name as well, because all intermediate rows are also being observed, the current row will automatically re-evaluate using the new value.
That’s a lot to process, so let’s recap:
- When reading any state, all state values used to derive the state (i.e. its “dependencies”) must also be “read” at the same time. This allows the snapshot system to track those dependencies.
- Snapshot state reads will be tracked no matter how deep down the call stack they are. We can read states in functions, even recursive functions, and they’ll still be observed.
By converting rows to calculate lazily (pull-based) instead of eagerly (push-based), we ensure that all values used to perform the evaluation of a row’s expression are observed when the row is read. But while we’ve fixed the observation problem, we’ve made the performance of this code even worse. If every row is asked for its result and errors, then we’ll calculate the expression twice, and calculate every row referenced by the current row twice as well in the process, even if between those calls nothing changed! That’s a lot of redundant work. We could maybe solve this by caching the evaluation results, but then we’d be back where we started: if we read a cached value, we would not read our dependencies, and so we wouldn’t get updated when they change. The only way this could work is if the cache could somehow communicate to the snapshot system what states were used to calculate its value, without actually having to read them again on every call.
Review: State vs MutableState
Let's take a quick detour and review the State and MutableState APIs really quick, because the distinction will be important shortly.
State<T> is a simple interface that defines a val value: T. It's read-only – if you only have a State, there's no way to change its value.
State<T>has an extension function,getValue(): T, which allows it to be used as a property delegate for read-only properties (i.e.val … by)
MutableState<T> extends State<T> and makes the value property writeable. It turns the val into a var.
MutableState<T>has its own extension function,setValue(value: T), which allows it to be used as writable a property delegate (i.e.var … by).
While the
Stateinterface might look simple (it just has a single property!), you probably don't want to implement it yourself unless you really know what you're doing. If you don’t believe me, take a look at the implementation of the class backingmutableStateOf.
It's a common pattern for classes to define properties as MutableStates, but only expose them as read-only States. That's exactly what our RowImpl does when we write this:
var result: Value? by mutableStateOf(null)
private set
Because the Row interface defines result as a read-only property, implementations can use a MutableState to back it under the hood, but they only really need to use a State. However, until now, mutableStateOf is the only way we've seen to create State objects.
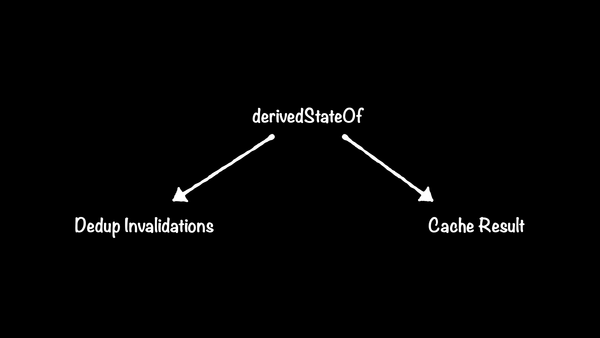
State dependencies: Introducing derivedStateOf
Compose provides another State<T> builder function: derivedStateOf<T>. Unlike mutableStateOf, which returns a MutableState, derivedStateOf only returns a State. Here’s what it looks like (source):
/**
* Creates a [State] object whose [State.value] is the result of [calculation]. The result of
* calculation will be cached in such a way that calling [State.value] repeatedly will not cause
* [calculation] to be executed multiple times, but reading [State.value] will cause all [State]
* objects that got read during the [calculation] to be read in the current [Snapshot], meaning
* that this will correctly subscribe to the derived state objects if the value is being read in
* an observed context such as a [Composable] function.
*
* @param calculation the calculation to create the value this state object represents.
*/
fun <T> derivedStateOf(calculation: () -> T): State<T>
There’s a lot to unpack there, so let’s break it down:
- “Creates a State object whose State.value is the result of calculation”
- It basically acts like a “map” operator. The returned State’s value will be whatever you return from the lambda. If the values read in the calculation change, the State value will reflect the new result.
- “The result of calculation will be cached in such a way that calling State.value repeatedly will not cause calculation to be executed multiple times”
- It does caching too! Once the result of the calculation has been performed, it can be read as often as you like without doing the work again. Reactive stream programmers can compare this to RxJava’s
replayor Flow’sshareIn.
- It does caching too! Once the result of the calculation has been performed, it can be read as often as you like without doing the work again. Reactive stream programmers can compare this to RxJava’s
- “reading State.value will cause all State objects that got read during the calculation to be read in the current Snapshot”
- This is where things get really interesting. If the returned state is read inside a snapshot observer, such as a composable function, then any changes to any of the values read by the lambda will be considered changes to this
State. This happens even if the value was cached, and the read doesn’t actually invoke the lambda again. This is arguably the most important feature ofderivedStateOf. It can cache the result of the lambda, but reading that cached value is, as far as the snapshot system is concerned, effectively the same thing as running the lambda again every time.
- This is where things get really interesting. If the returned state is read inside a snapshot observer, such as a composable function, then any changes to any of the values read by the lambda will be considered changes to this
Remember how we were wishing for a way to cache state computations that also ensured changes to upstream values would also trigger downstream updates? That's exactly what derivedStateOf does. It actually goes one step further, and will only notify observers of changes if the result of the computation actually changes – if different inputs result in the same computed value, readers of the computed value will be left alone. You can perform complex computations in the derivedStateOf lambda and be assured that your readers will only update when there's actually new data for them to process.
Let's demonstrate how this works with a small example (and let's drop the property delegation sugar in favor of explicit types to show what's going on more clearly):
val name: MutableState<String> = mutableStateOf("")
val hello: String get() = "Hello, ${name.value.toLowercase()}!"
@Composable fun HelloWorld() {
Column {
TextField(
value = name.value,
onValueChange = { name.value = it }
)
Text(hello)
}
}
This code gives us a simple UI where you can enter your name and it says hello. The hello property is a computed property – every time it's read, it reads name. So when the composable reads hello, it automatically observes changes to name. This is just like our last refactor of RowImpl. Now let's change this code to use derivedStateOf:
val name: MutableState<String> = mutableStateOf("")
val hello: State<String> = derivedStateOf(structuralEqualityPolicy()) {
"Hello, ${name.value.toLowercase()}!"
}
@Composable fun HelloWorld() {
Column {
TextField(
value = name.value,
onValueChange = { name.value = it }
)
// Note that hello is now a State, so we
// need to use the value property.
Text(hello.value)
}
}
The composable works the same way (except for the addition of .value), but hello is doing a lot more: the message string is only computed once, when the name actually changes, and then cached. If our composable recomposes a bunch of times, or hello is read in other places, it won't re-compute the message. However, when name changes, any composables or other snapshot observers that read hello will also be notified, even if they didn't read name directly. This is exactly what we were looking for! Reads that also track state dependencies, and caching! Also, if the current name is changed to have a different capitalization (e.g. "Sam" -> "SAM"), because name converts both of them to the same lowercase value, that change won't require readers of hello to update.
derivedStateOf, always pass an explicit policy parameter to avoid invalidating when the calculation result doesn't change.In most cases you can probably pass
structuralEqualityPolicy() (which is also the default for mutableStateOf).Let's go back to our Row implementation and use our new toy:
class RowImpl : Row {
var previousRow: RowImpl? by mutableStateOf(null)
override var input: String by mutableStateOf("")
private val parseResult by derivedStateOf {
parse(input)
}
/**
* If the parse was successful, evaluate the expression in the parent’s context, then cache it until at least one of:
* - our previous row changes
* - our previous row’s name or result changes
* - our expression changes (e.g. because [input] changed)
*/
private val evalResult by derivedStateOf(structuralEqualityPolicy()) {
val evalContext = previousRow?.evaluationContext
?: EmptyEvaluationContext
parseResult.expression?.evaluate(evalContext)
}
override val result: Value?
get() = evalResult?.value
override val errors: List<String>
get() = parseResult.errors + evalResult?.errors.orEmpty()
val evaluationContext = object : EvaluationContext {
override fun getValueForName(name: String): Value? {
// If our name matches, we're done!
return if (name == evalResult?.assignedName) result else {
// Continue searching up the worksheet.
previousRow?.evaluationContext
?.getValueForName(name)
}
}
}
}
There’s quite a few changes there so let’s review them one-by-one:
parseResult– Parses the input, caches the resulting expression until the input changes.evalResult– If the parse was successful, evaluate the expression, then cache it until at least one of:- The previous row is changed to a different value. Can’t happen in our current code, but could if we add support for inserting rows in the middle of the worksheet.
- If, and only if, our expression references another name, then if that row’s name or result changes, or another row in between this and that is changed to assign that name. This works because of the recursive reading of parent row properties explained earlier.
- Our expression changes (e.g. because [input] changed).
result– If evaluation was successful, returns this row’s value. Because it’s not doing any real work there’s no reason to wrap it inderivedStateOf. Any code readingresultwill track changes toevalResult, which is aState, so this property still propagates changes.errors– This still just concatenates the two error sources. It’s not wrapped in aderivedStateOffor the same reason thatresultisn’t.
Tying it all together (aka "row-ping" it up)
We're almost finished. We've built a smart implementation of the Row interface that is fully reactive using snapshot state. Rows can be chained in a linked list, and will automatically recalculate when previous rows that they depend on are changed. It's not great that we are asking consumers of our library to manually manage a linked list though, so let's make a new interface that does that for us:
interface Worksheet {
/** Read-only (but not necessarily immutable) list of rows. */
val rows: List<Row>
/** Inserts an empty row at the end of the list. */
fun addRow()
}
We need to expose our linked list of rows as a Kotlin List type, and allow indexed access. There are multiple ways to implement this interface. We could back the rows property with a MutableState<List<Row>>, or use Compose's mutableStateListOf to create a SnapshotStateList<Row>. Both approaches will ensure that readers are always notified of changes. Let's use Compose's list type:
class WorksheetImpl : Worksheet {
// Use a private backing property because we need to be able
// to mutate the list internally. We also need to be able to access
// the [RowImpl.previousRow] property, so the element type needs
// to be [RowImpl] instead of [Row].
private val _rows: MutableList<RowImpl> = mutableStateListOf()
// We don't need to use derivedStateOf here because we're just
// proxying another property to hide its types – we're not actually
// computing anything.
// Note that because [List] is covariant on its element type, Kotlin
// automatically knows that a mutable list of a subtype of Row
// is also a List of Row.
override val rows: List<Row> get() = _rows
override fun addRow() {
_rows += RowImpl().apply {
// Add new rows to the linked list as well as the indexed one.
previousRow = _rows.lastOrNull()
}
}
}
And that's it! Now we can use Worksheet to build an app. Slapping a beautiful UI on top of this is left as an exercise for the reader. You can start with the RowEditor function we defined earlier, or just clone the GitHub project for this post, which has an implementation of the calculation library as well as a basic UI layer (and more features, like highlighting errors in the input string).
Conclusion
Jetpack Compose's snapshot state system is a powerful way to manage mutable state and write code that is reactive by default. The derivedStateOf function is an essential tool to have in your toolbox. It helps you to ensure that data flows efficiently through your programs while keeping them reactive. For more information on how derivedStateOf works, check out How derivedStateOf works: a deep d(er)ive.
Also, check out my other articles about Compose state.
Thanks to Laura Kelly for reviewing this post!